
These are my notes for the third and final tutorial of useR2018, and the tutorial I was looking forward to the most. I struggle with missing value imputation. It’s one of those things which I kind of get the theory of, but fall over when trying to do. So I was keen to hear Julie Joss and Nick Tierney talk about their techniques and associated R packages.
tweet removed due to API changes
I ran into a wall pretty early on here in that I wasn’t very comfortable with Principal Component Analysis (PCA). I took the opportunity to learn a bit more about this common technique, and try to understand the intuition behind it.
The data and slides for Julie’s and Nick’s tutorial are available on Nick’s GitHub.
Required packages:
install.packages(c("tidyverse", "ggplot2", "naniar", "visdat", "missMDA"))Ozone data set
The data in use today is the Ozone data set from Airbreizh, a French association that monitors air quality. We’re only going to focus on the quantitative variables here, so we will drop the WindDirection variable.
ozone <- read_csv("ozoneNA.csv") %>%
select(-X1, -WindDirection) # unnecessary row index
#> Parsed with column specification:
#> cols(
#> X1 = col_double(),
#> maxO3 = col_double(),
#> T9 = col_double(),
#> T12 = col_double(),
#> T15 = col_double(),
#> Ne9 = col_double(),
#> Ne12 = col_double(),
#> Ne15 = col_double(),
#> Vx9 = col_double(),
#> Vx12 = col_double(),
#> Vx15 = col_double(),
#> maxO3v = col_double(),
#> WindDirection = col_character()
#> )Patterns of missing data
The easiest way to deal with missing data is to delete it. But this ignores any pattern in the missing data, as well as any mechanism that leads to missing values. Some data sets can also contain a majority of values that have at least one missing value, and so deleting missing values would delete most of the data!
Missing values occur in three main patterns based on their relationship with the observed and even the unobserved variables of the data:
- Missing Completely at Random (MCAR): probability of data being missing is independent of the observed and unobserved variables.
- Missing at Random (MAR): probability is not independent of the observed values (ie. is not random) but the observed variables do not fully account for the pattern. In this case, there may be unobserved variables affecting the probability that the data will be missing.
- Missing not at random (MNAR): probability of data being missing depends on the observed values of the data.
Visualising missing data
Multiple correspondence analysis visualises data in such a way that relationships between missing values are often made apparent. One implementation of this is the naniar package:
vis_miss(ozone)
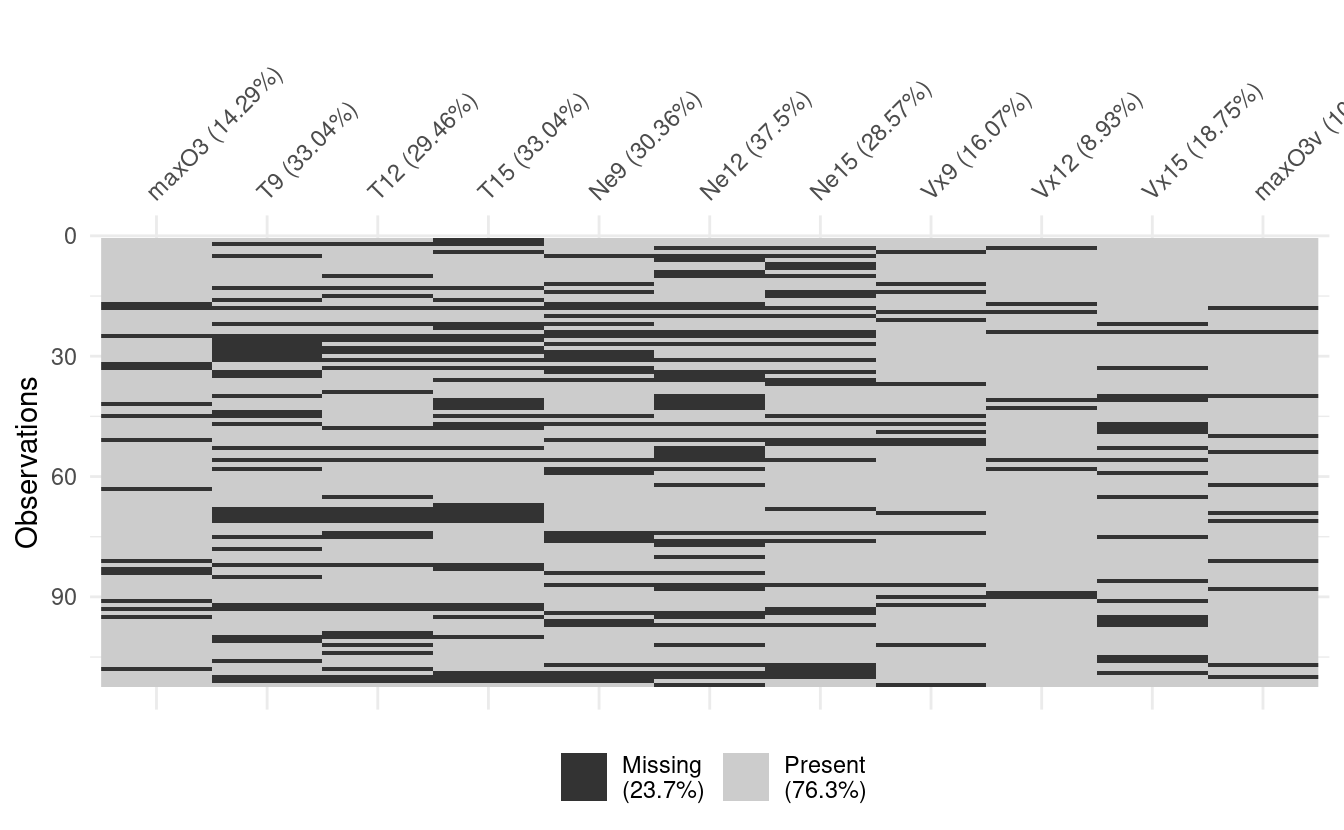
We can repeat the visualisation with an option to cluster the missing values, making it easier to spot patterns, if any.
vis_miss(ozone, cluster = TRUE)
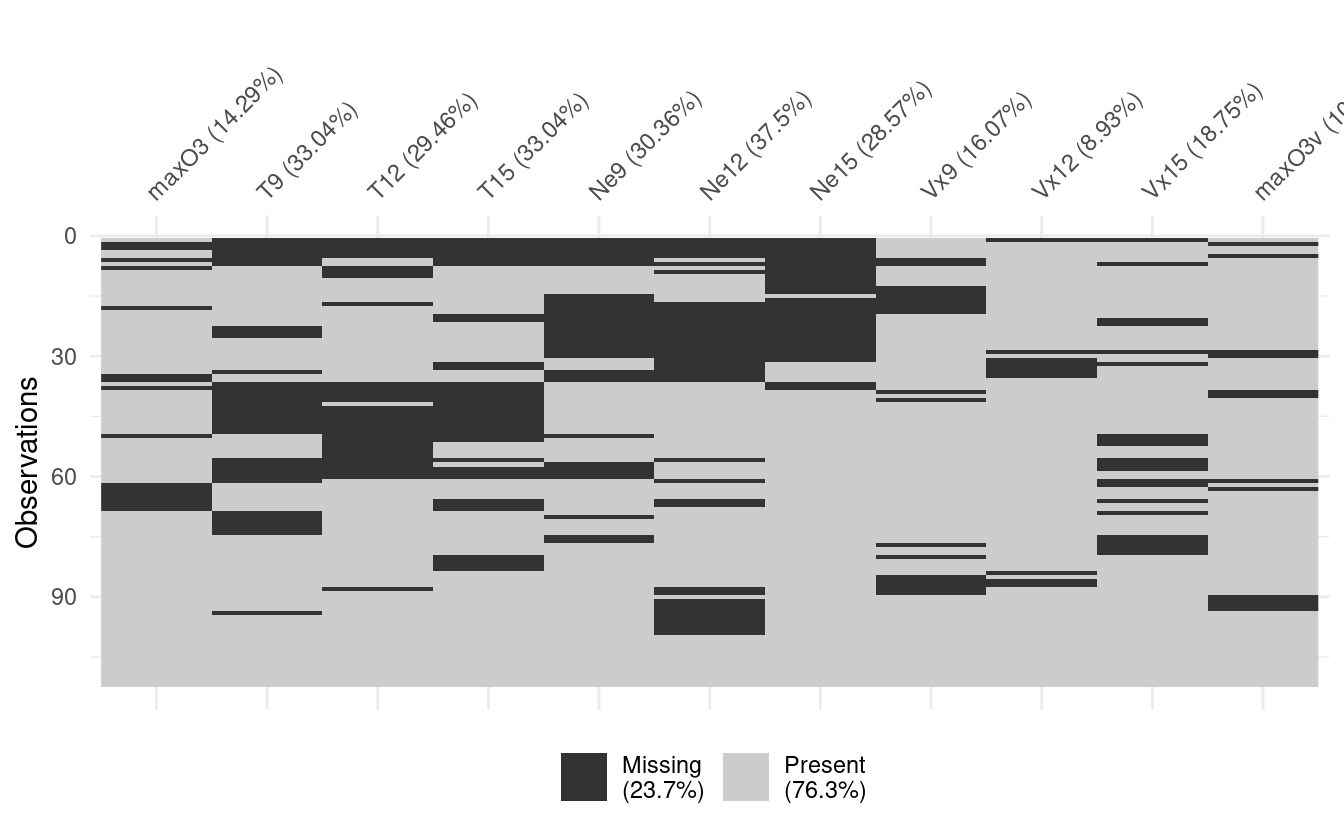
Dealing with missing values
Suppose we don’t want to delete our missing data and pretend that everything is fine. Then we might look to impute the missing values. That is to say, we might want to look at the data we do have to determine what the missing values might have been.
One of the easiest methods of imputation is that of mean imputation. In this case, we replace all of the missing values by the mean of the present values of the given variable.
We could also define a model on the present values of the data to predict what the missing value might have been. A simple linear regression might suffice.
A more sophisticated method involves the use of Principal Component Analysis.
A refresher on PCA
I don’t understand Principal Component Analysis (PCA). Believe me, I’ve tried.
The goal of PCA is to find the subspace that best represents the data. The outcome of PCA is a set of uncorrelated variables called principal components.
This is a wonderful (but long) article on PCA (pdf). It’s gentle without being patronising. I’ll highlight some points in the article here, but it’s well worth finding the time to read the article in full.
First of all, recall the definition of an eigenvector. You probably encountered this in your first or second year of university, and then promptly forgot it. In the example below, the column vector (6,4)T is an eigenvector of the square matrix, because the result of the matrix multiplication is a scale multiple of (6,4)T. In other words, the square matrix makes the eigenvector bigger, but it doesn’t change its direction. The scalar multiple is 4, and that’s the eigenvalue associated with the eigenvector.
$$ \left(\begin{array}{cc} 2 & 3 \\ 2 & 1 \end{array}\right) \times \left(\begin{array}{c} 6 \\ 4 \end{array}\right) = \left(\begin{array}{c} 24 \\ 16 \end{array}\right) = 4 \left(\begin{array}{c} 6 \\ 4 \end{array}\right) $$ But how does this relate to stats? Well a data set gives rise to a covariance matrix, in which the ijth cell of the matrix is the covariance between the ith variable and the jth variable (the variance of each variable sits along the diagonal). This is a square matrix, so we can find some eigenvectors.
I don’t remember a whole lot of the linear algebra I learnt a long time ago, so I had to be reminded of two quick theorems in play here. A covariance matrix is symmetric, so we can make use of the following:
- Eigenvectors of real symmetric matrices are real
- Eigenvectors of real symmetric matrices are orthogonal
tweet removed due to API changes
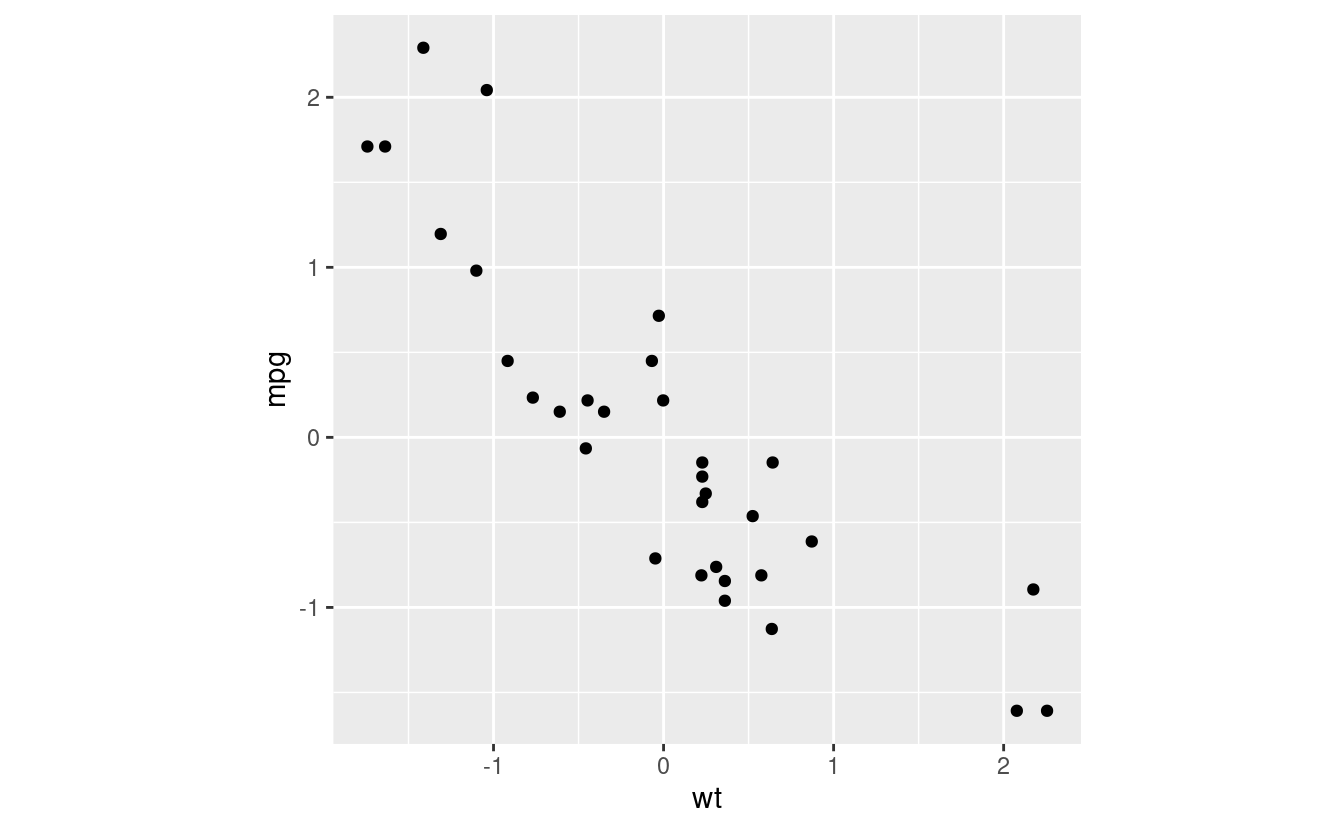
Let’s go through an example. Take the classic mtcars data set, and draw a scatterplot between wt (weight) and mpg (miles per gallon). We’re going to work on data that’s been centered and rescaled so as to make the eigenvectors look right, as well as for other reasons that will become apparent soon.
mtcars_scaled <- mtcars %>%
select(wt, mpg) %>%
mutate_all(scale)
mtcars_scaled %>% ggplot(aes(x = wt, y = mpg)) +
geom_point() +
coord_fixed() # makes the plot square
Let’s calculate the PCA eigenvectors. These are eigenvectors of the covariance matrix. Because we have two variables we have two eigenvectors (another property of symmetric matrices), which we’ll call PC1 and PC2. You don’t need a install a package to calculate these, as we can use the preinstalled prcomp function.
PC <- prcomp(~ wt + mpg, data = mtcars_scaled)
PC
#> Standard deviations (1, .., p=2):
#> [1] 1.3666233 0.3637865
#>
#> Rotation (n x k) = (2 x 2):
#> PC1 PC2
#> wt 0.7071068 0.7071068
#> mpg -0.7071068 0.7071068PC1 <- PC$rotation[,1]
PC2 <- PC$rotation[,2]
mtcars_scaled %>% ggplot(aes(x = wt, y = mpg)) +
geom_point() +
geom_segment(aes(x = 0, xend = PC1[["wt"]], y = 0, yend = PC1[["mpg"]]), arrow = arrow(length = unit(0.5, "cm")), col = "red") +
geom_segment(aes(x = 0, xend = PC2[["wt"]], y = 0, yend = PC2[["mpg"]]), arrow = arrow(length = unit(0.5, "cm")), col = "red") +
coord_fixed() # makes the plot square
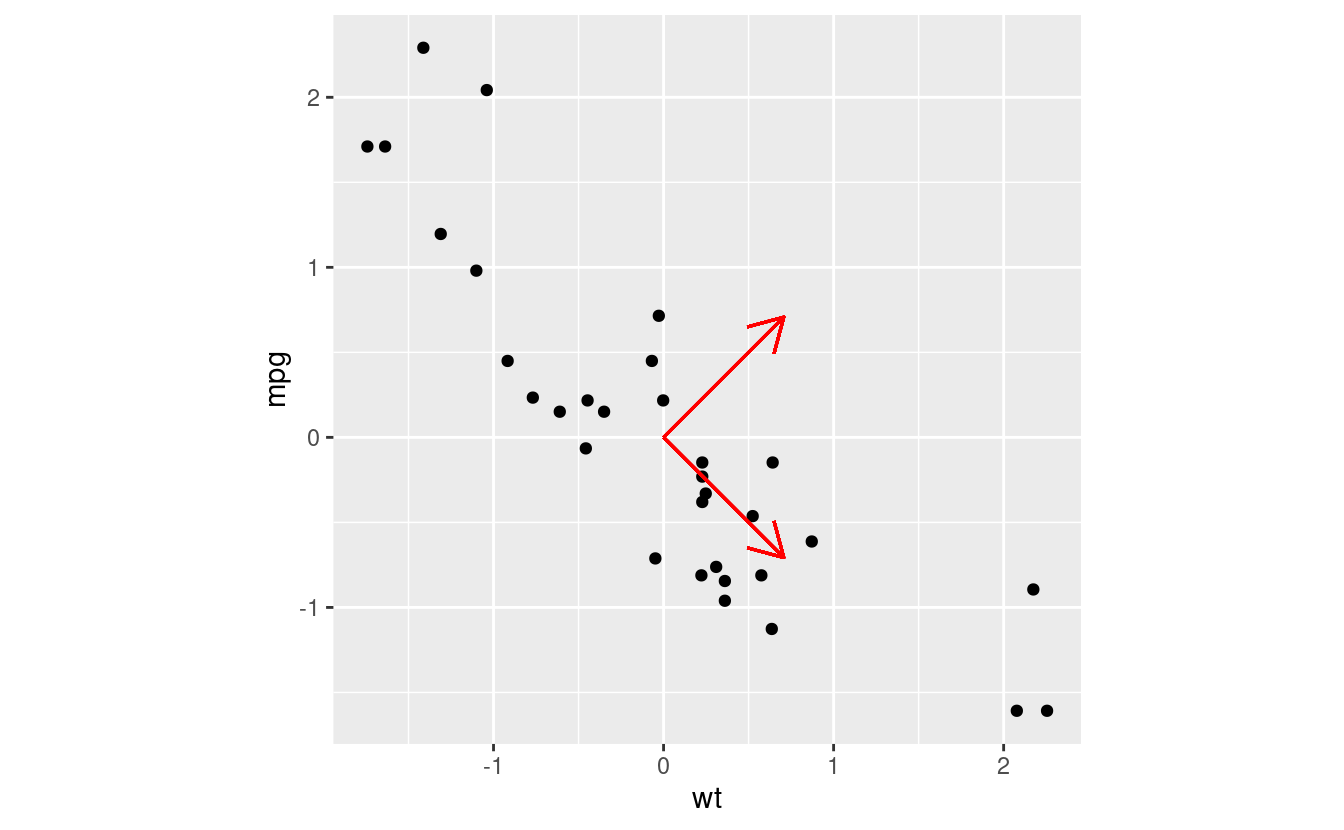
Look at those eigenvectors! The eigenvectors used in PCA are always normalised, so that the magnitude of the vectors are all 1. That is, we have some mutually orthogonal unit vectors…it’s a change of basis! Any point in the data set can be described by the original x and y axes, but it can also be described by a linear combination of our new PC eigenvectors!
So we haven’t done anything to the data yet, apart from some basic scaling and centering. But every eigenvector has an associated eigenvalue. In this case, the higher the eigenvalue, the more the eigenvector is stretched by the (modified) covariance matrix. That is to say, the higher the eigenvalue, the more variance explained by the eigenvector. This is why we had to rescale the data so that each variable starts with a variance of 1—if we didn’t, the variables with higher variance, such as mpg, would appear artifically more important.
summary(PC)
#> Importance of components:
#> PC1 PC2
#> Standard deviation 1.3666 0.36379
#> Proportion of Variance 0.9338 0.06617
#> Cumulative Proportion 0.9338 1.00000PCA’s primary use is for dimension reduction. You can use the ranking of the eigenvalues to determine what eigenvectors contribute the most to the variance of the data. You’ll drop a dimension by losing some of your information, but it will be the least valuable information.
PCA imputation
At this point I had re-learnt enough PCA to get by, Time to revisit the matter of missing data!
Here’s how this works. First we need to choose a number of dimensions S to keep at each step (more about this later).
- Start with mean imputation, which assigns the variable mean to every missing value.
- Apply PCA and keep S dimensions.
- Re-impute the missing values with the new mean.
- Repeat steps 2 and 3 until the values converge.
The missMDA package handles this for us. First we need to work out how many dimensions we want to keep when doing our PCA. The missMDA package contains an estim_ncpPCA function that helps us determine the value of S that minimises the mean squared error of prediction (MSEP).
nb <- estim_ncpPCA(ozone, method.cv = "Kfold")ggplot(data = NULL, aes(x = 0:5, y = nb$criterion)) +
geom_point() +
geom_line() +
xlab("nb dim") +
ylab("MSEP")
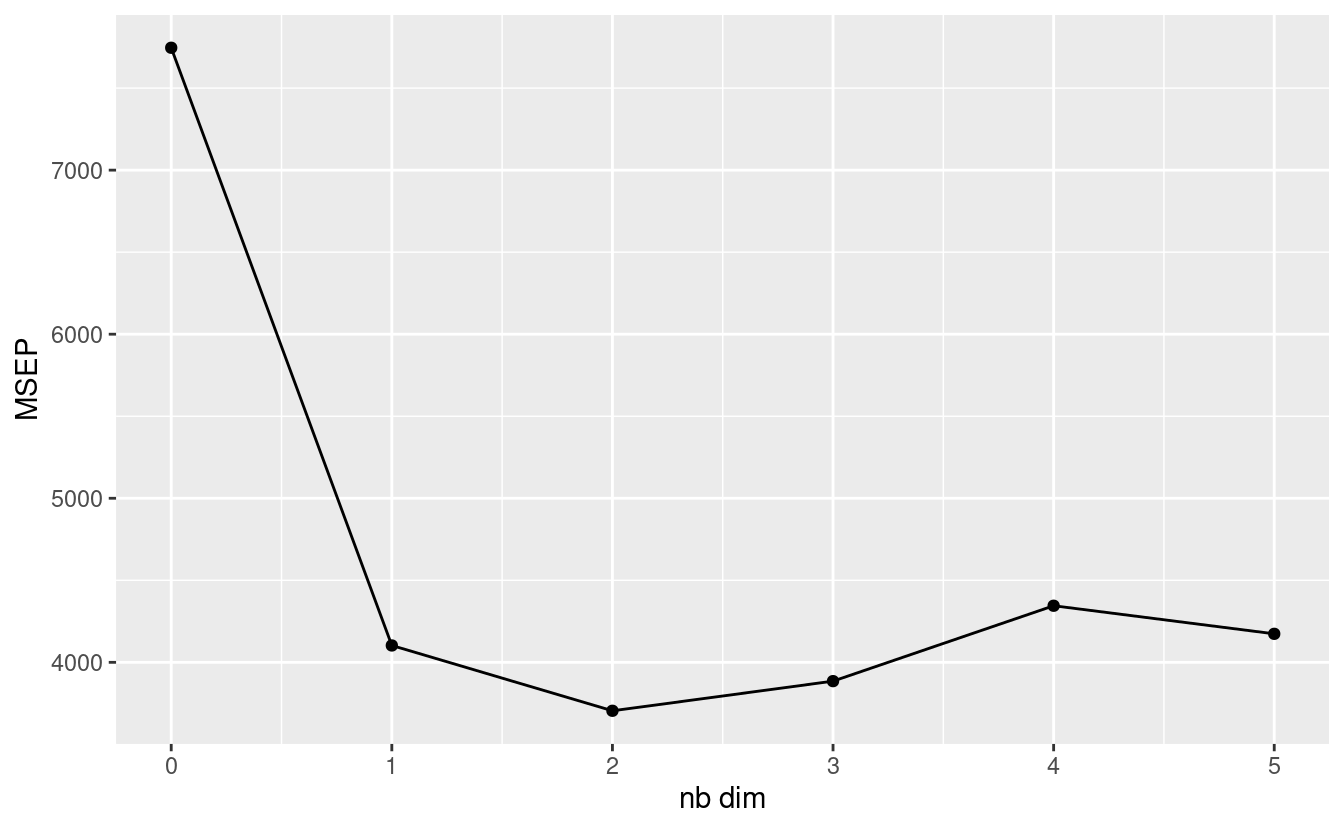
We can see that the MSEP is minimised when the S is 2, a number we can also access with nb$ncp. We can now perform the actual PCA imputation. This doesn’t work with tibbles, so I convert the data to a data frame before piping it into the impute function.
ozone_comp <- ozone %>% as.data.frame %>% imputePCA(ncp = nb$ncp)Now let’s compare the original data to the complete data. The imputePCA function returns a list, which we convert to a tibble. There are also some new columns containing fitted values, which we’ll set aside for an easier comparison.
We’ll also remove the completedObs. prefix of the variable names. The regex pattern used here, ".*(?<=\\.)", matches everything up to and including the last dot in the column names. I use this pattern * a lot*. Note that you’ll need perl = TRUE to use the lookahead.
ozone %>% head
#> # A tibble: 6 x 11
#> maxO3 T9 T12 T15 Ne9 Ne12 Ne15 Vx9 Vx12 Vx15 maxO3v
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 87 15.6 18.5 NA 4 4 8 0.695 -1.71 -0.695 84
#> 2 82 NA NA NA 5 5 7 -4.33 -4 -3 87
#> 3 92 15.3 17.6 19.5 2 NA NA 2.95 NA 0.521 82
#> 4 114 16.2 19.7 NA 1 1 0 NA 0.347 -0.174 92
#> 5 94 NA 20.5 20.4 NA NA NA -0.5 -2.95 -4.33 114
#> 6 80 17.7 19.8 18.3 6 NA 7 -5.64 -5 -6 94
ozone_comp %>%
as.data.frame %>% # seems to need this intermediate step?
as_tibble %>%
select(contains("complete")) %>%
rename_all(gsub, pattern = ".*(?<=\\.)", replacement = '', perl = TRUE) %>%
head
#> # A tibble: 6 x 11
#> maxO3 T9 T12 T15 Ne9 Ne12 Ne15 Vx9 Vx12 Vx15 maxO3v
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 87 15.6 18.5 20.5 4 4 8 0.695 -1.71 -0.695 84
#> 2 82 18.5 20.9 21.8 5 5 7 -4.33 -4 -3 87
#> 3 92 15.3 17.6 19.5 2 3.98 3.81 2.95 1.95 0.521 82
#> 4 114 16.2 19.7 24.7 1 1 0 2.04 0.347 -0.174 92
#> 5 94 19.0 20.5 20.4 5.29 5.27 5.06 -0.5 -2.95 -4.33 114
#> 6 80 17.7 19.8 18.3 6 7.02 7 -5.64 -5 -6 94I missed a lot
Because I was catching up on PCA, I missed a fair chunk of the tutorial. In particular, I missed a whole discussion on evaluating how well the missing data was imputed. I also missed some stuff on random forests, and I love random forests!
But I learnt a tonne, and I’m grateful for the opportunity to dig into two topics I usually struggle with: PCA and missing value imputation. Thank you to Julie and Nick for the tutorial.
Now, onward to the official launch of the #useR2018!
devtools::session_info()
#> ─ Session info ───────────────────────────────────────────────────────────────
#> setting value
#> version R version 4.0.0 (2020-04-24)
#> os Ubuntu 20.04 LTS
#> system x86_64, linux-gnu
#> ui X11
#> language en_AU:en
#> collate en_AU.UTF-8
#> ctype en_AU.UTF-8
#> tz Australia/Melbourne
#> date 2020-06-13
#>
#> ─ Packages ───────────────────────────────────────────────────────────────────
#> package * version date lib source
#> assertthat 0.2.1 2019-03-21 [1] CRAN (R 4.0.0)
#> backports 1.1.7 2020-05-13 [1] CRAN (R 4.0.0)
#> blogdown 0.19 2020-05-22 [1] CRAN (R 4.0.0)
#> broom 0.5.6 2020-04-20 [1] CRAN (R 4.0.0)
#> callr 3.4.3 2020-03-28 [1] CRAN (R 4.0.0)
#> cellranger 1.1.0 2016-07-27 [1] CRAN (R 4.0.0)
#> cli 2.0.2 2020-02-28 [1] CRAN (R 4.0.0)
#> cluster 2.1.0 2019-06-19 [4] CRAN (R 4.0.0)
#> codetools 0.2-16 2018-12-24 [4] CRAN (R 4.0.0)
#> colorspace 1.4-1 2019-03-18 [1] CRAN (R 4.0.0)
#> crayon 1.3.4 2017-09-16 [1] CRAN (R 4.0.0)
#> DBI 1.1.0 2019-12-15 [1] CRAN (R 4.0.0)
#> dbplyr 1.4.3 2020-04-19 [1] CRAN (R 4.0.0)
#> desc 1.2.0 2018-05-01 [1] CRAN (R 4.0.0)
#> devtools 2.3.0 2020-04-10 [1] CRAN (R 4.0.0)
#> digest 0.6.25 2020-02-23 [1] CRAN (R 4.0.0)
#> doParallel 1.0.15 2019-08-02 [1] CRAN (R 4.0.0)
#> downlit 0.0.0.9000 2020-06-12 [1] Github (r-lib/downlit@87fb1af)
#> dplyr * 0.8.5 2020-03-07 [1] CRAN (R 4.0.0)
#> ellipsis 0.3.1 2020-05-15 [1] CRAN (R 4.0.0)
#> evaluate 0.14 2019-05-28 [1] CRAN (R 4.0.0)
#> FactoMineR 2.3 2020-02-29 [1] CRAN (R 4.0.0)
#> fansi 0.4.1 2020-01-08 [1] CRAN (R 4.0.0)
#> farver 2.0.3 2020-01-16 [1] CRAN (R 4.0.0)
#> flashClust 1.01-2 2012-08-21 [1] CRAN (R 4.0.0)
#> forcats * 0.5.0 2020-03-01 [1] CRAN (R 4.0.0)
#> foreach 1.5.0 2020-03-30 [1] CRAN (R 4.0.0)
#> fs 1.4.1 2020-04-04 [1] CRAN (R 4.0.0)
#> generics 0.0.2 2018-11-29 [1] CRAN (R 4.0.0)
#> ggplot2 * 3.3.0 2020-03-05 [1] CRAN (R 4.0.0)
#> ggrepel 0.8.2 2020-03-08 [1] CRAN (R 4.0.0)
#> glue 1.4.1 2020-05-13 [1] CRAN (R 4.0.0)
#> gtable 0.3.0 2019-03-25 [1] CRAN (R 4.0.0)
#> haven 2.2.0 2019-11-08 [1] CRAN (R 4.0.0)
#> hms 0.5.3 2020-01-08 [1] CRAN (R 4.0.0)
#> htmltools 0.4.0 2019-10-04 [1] CRAN (R 4.0.0)
#> httr 1.4.1 2019-08-05 [1] CRAN (R 4.0.0)
#> hugodown 0.0.0.9000 2020-06-12 [1] Github (r-lib/hugodown@6812ada)
#> iterators 1.0.12 2019-07-26 [1] CRAN (R 4.0.0)
#> jsonlite 1.6.1 2020-02-02 [1] CRAN (R 4.0.0)
#> knitr 1.28 2020-02-06 [1] CRAN (R 4.0.0)
#> labeling 0.3 2014-08-23 [1] CRAN (R 4.0.0)
#> lattice 0.20-41 2020-04-02 [4] CRAN (R 4.0.0)
#> leaps 3.1 2020-01-16 [1] CRAN (R 4.0.0)
#> lifecycle 0.2.0 2020-03-06 [1] CRAN (R 4.0.0)
#> lubridate 1.7.8 2020-04-06 [1] CRAN (R 4.0.0)
#> magrittr 1.5 2014-11-22 [1] CRAN (R 4.0.0)
#> MASS 7.3-51.6 2020-04-26 [4] CRAN (R 4.0.0)
#> memoise 1.1.0.9000 2020-05-09 [1] Github (hadley/memoise@4aefd9f)
#> mice 3.9.0 2020-05-14 [1] CRAN (R 4.0.0)
#> missMDA * 1.17 2020-05-19 [1] CRAN (R 4.0.0)
#> modelr 0.1.6 2020-02-22 [1] CRAN (R 4.0.0)
#> munsell 0.5.0 2018-06-12 [1] CRAN (R 4.0.0)
#> mvtnorm 1.1-0 2020-02-24 [1] CRAN (R 4.0.0)
#> naniar * 0.5.1 2020-04-30 [1] CRAN (R 4.0.0)
#> nlme 3.1-145 2020-03-04 [4] CRAN (R 4.0.0)
#> pillar 1.4.4 2020-05-05 [1] CRAN (R 4.0.0)
#> pkgbuild 1.0.7 2020-04-25 [1] CRAN (R 4.0.0)
#> pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.0.0)
#> pkgload 1.0.2 2018-10-29 [1] CRAN (R 4.0.0)
#> prettyunits 1.1.1 2020-01-24 [1] CRAN (R 4.0.0)
#> processx 3.4.2 2020-02-09 [1] CRAN (R 4.0.0)
#> ps 1.3.3 2020-05-08 [1] CRAN (R 4.0.0)
#> purrr * 0.3.4 2020-04-17 [1] CRAN (R 4.0.0)
#> R6 2.4.1 2019-11-12 [1] CRAN (R 4.0.0)
#> Rcpp 1.0.4.6 2020-04-09 [1] CRAN (R 4.0.0)
#> readr * 1.3.1 2018-12-21 [1] CRAN (R 4.0.0)
#> readxl 1.3.1 2019-03-13 [1] CRAN (R 4.0.0)
#> remotes 2.1.1 2020-02-15 [1] CRAN (R 4.0.0)
#> reprex 0.3.0 2019-05-16 [1] CRAN (R 4.0.0)
#> rlang 0.4.6 2020-05-02 [1] CRAN (R 4.0.0)
#> rmarkdown 2.2.3 2020-06-12 [1] Github (rstudio/rmarkdown@4ee96c8)
#> rprojroot 1.3-2 2018-01-03 [1] CRAN (R 4.0.0)
#> rstudioapi 0.11 2020-02-07 [1] CRAN (R 4.0.0)
#> rvest 0.3.5 2019-11-08 [1] CRAN (R 4.0.0)
#> scales 1.1.0 2019-11-18 [1] CRAN (R 4.0.0)
#> scatterplot3d 0.3-41 2018-03-14 [1] CRAN (R 4.0.0)
#> sessioninfo 1.1.1 2018-11-05 [1] CRAN (R 4.0.0)
#> stringi 1.4.6 2020-02-17 [1] CRAN (R 4.0.0)
#> stringr * 1.4.0 2019-02-10 [1] CRAN (R 4.0.0)
#> testthat 2.3.2 2020-03-02 [1] CRAN (R 4.0.0)
#> tibble * 3.0.1 2020-04-20 [1] CRAN (R 4.0.0)
#> tidyr * 1.0.2 2020-01-24 [1] CRAN (R 4.0.0)
#> tidyselect 1.0.0 2020-01-27 [1] CRAN (R 4.0.0)
#> tidyverse * 1.3.0 2019-11-21 [1] CRAN (R 4.0.0)
#> usethis 1.6.1 2020-04-29 [1] CRAN (R 4.0.0)
#> utf8 1.1.4 2018-05-24 [1] CRAN (R 4.0.0)
#> vctrs 0.3.1 2020-06-05 [1] CRAN (R 4.0.0)
#> visdat * 0.5.3 2019-02-15 [1] CRAN (R 4.0.0)
#> withr 2.2.0 2020-04-20 [1] CRAN (R 4.0.0)
#> xfun 0.14 2020-05-20 [1] CRAN (R 4.0.0)
#> xml2 1.3.2 2020-04-23 [1] CRAN (R 4.0.0)
#> yaml 2.2.1 2020-02-01 [1] CRAN (R 4.0.0)
#>
#> [1] /home/mdneuzerling/R/x86_64-pc-linux-gnu-library/4.0
#> [2] /usr/local/lib/R/site-library
#> [3] /usr/lib/R/site-library
#> [4] /usr/lib/R/library