If you listen to university advertisements for data science masters degrees, you’d believe that data scientists are so in-demand that they can walk into any company, state their salary, and start work straight away.
Not quite.
Interviewing for data science positions is tough, and job-seekers face some bad behaviour from recruiters and hiring managers. Many companies understand that they need to do something with data, but they don’t know what. They’ll say they want machine learning when they really want a few dashboards. I’ve fallen for it.
I’m going to put some advice here for anyone about to face the same job market. This is lifted from my own experience, when I was looking for a job a while back.
A few notes about where I was at when I was hunting for this job, in case your circumstances are different: This wasn’t my first job, and I understand that fresh graduates can’t afford to be as selective as I was. I was specifically looking for something with a machine learning focus. And keep in mind that everything here is written from an Australian perspective.
Advice for job-seekers
Verify the position description
Simply put, make sure that the job that was advertised is the job that you’re interviewing for.
Companies understand that they need to do something with data. Machine learning, R, Python, etc. are trendy right now, so sometimes they put these terms into their job requirements without really understanding why. You need to cut through this.
I was once grilled in a phone interview for 20 minutes over my knowledge of random forests and modelling in R. After all that I asked how R or machine learning would be used in the role. Not at all! It turns out the company wanted a candidate with the capacity to train a model, but they didn’t think it was important that those skills were actually used.
Ask some simple questions to test if the position description is genuine. If the advertisement mentions R/Python, ask how R/Python is currently used in the team. If the advertisement talks about “advanced analytics” or “machine learning”, ask what machine learning models are currently in production.
Focus on what the team is doing now, not their aspirations
Aspirations are good—you wouldn’t want to work for a team without them. But while you’re waiting for your new team to meet those aspirations your skills are stagnating. This is especially true when talking about machine learning.
Introducing the first machine learning model to an organisation is a huge task. It takes time, and during that time you may not be doing the job you were hired to do. If the implementation of machine learning fails or if there’s a restructure and you’re moved to a different team, those aspirations won’t mean anything.
Make sure that your skills and goals align with the team as it exists now. If your next role must include machine learning, ask about machine learning models currently in use. Listen for phrases like “we’re getting into” and “we’re hoping to start doing”. Don’t let them sell you a dream.
There’s an exception here if the team you’re joining is being spun up solely to focus on machine learning. Otherwise, watch out for the word “transformation”.
Make sure the team can scope analytics work
Analytics teams are inundated with ad hoc requests, and these don’t always produce something of substantial value. Some people want cost-benefit analyses, a dashboard to track a metric, or a new report to send up the chain. It takes a talented data professional supported by a strong people leader to sort through these requests and decide what does and doesn’t have value.
A bad team will treat this as a prioritisation problem—every request has to be honoured, it’s just a matter of working out when. A good team will ask the right questions to determine if there’s any value to the task, and reject the task if it’s low-value. You want to make sure the team you’re going to work for is capable of this.
You won’t know for sure until you start working there, but here are some things to think about in the interview:
- How does the team value a piece of analytics work? What questions do they ask their stakeholders to determine this?
- When a team receives a piece of ad hoc work, where does it go? Is there a backlog, or some sort of sprint planning?
- Ask the team to estimate what proportion of their work is spent on long-term projects.
- How does the team push back on ad hoc work from a superior?
Watch out for combination jobs
Job advertisements for “Data Scientist/Data Engineer” or “Data Scientist/Software Developer” stick out as red flags. These are indicators that a company doesn’t know what they want in a candidate, so they’re hoping to hire a single person to do “all things data”.
Obviously there’s an exception here for small companies for whom specialisation is a luxury. But any moderately sized company serious about data should be building a team of complementary skills, rather than trying to hire an “all-in-one” candidate.
A word of advice to companies out there who think they need to take this approach to hiring: work out which part of the job is more important, and move the other part to the body of the advertisement. Rather than a “Data Scientist/Software Developer”, advertise for a Data Scientist, but point out that some software development experience would be viewed favourably. Bonus points if you can explain why those skills matter for the role!
I can’t imagine that there are too many people out there who can confidently bill themselves as experienced data scientists and experienced software developers. I hope they’re paid well.
Respect yourself
Some companies forget that recruitment is a two-sided process. Faced with more candidates than time, they can implement hiring practices that range from pointless to demeaning, or even downright illegal. I experienced:
- Pre-recorded video interviews, in which I was asked to record my answer to a question and send it in to be reviewed later.
- One-hour handwritten exams, in which I was asked to write code and even specify a logistic regression from memory.
- Questions about my “family situation”.
In each of these situations I walked away from the role. But I was in a position in which I could walk away. If you’ve got rent to pay then you may have to subject yourself to bad hiring practices, and you shouldn’t be shamed for that.
Some advice to employers: handwritten code tests are only acceptable if handwritten code is a big part of the role. Handwritten code should never be a big part of the role, so handwritten code tests are never acceptable.
There are some great companies out there
Don’t think that it’s all bad. Some companies out there are doing truly amazing stuff with data. Some of the projects I heard were innovative, interesting, and not evil!
The good jobs are out there. After all, I’ve got one now!
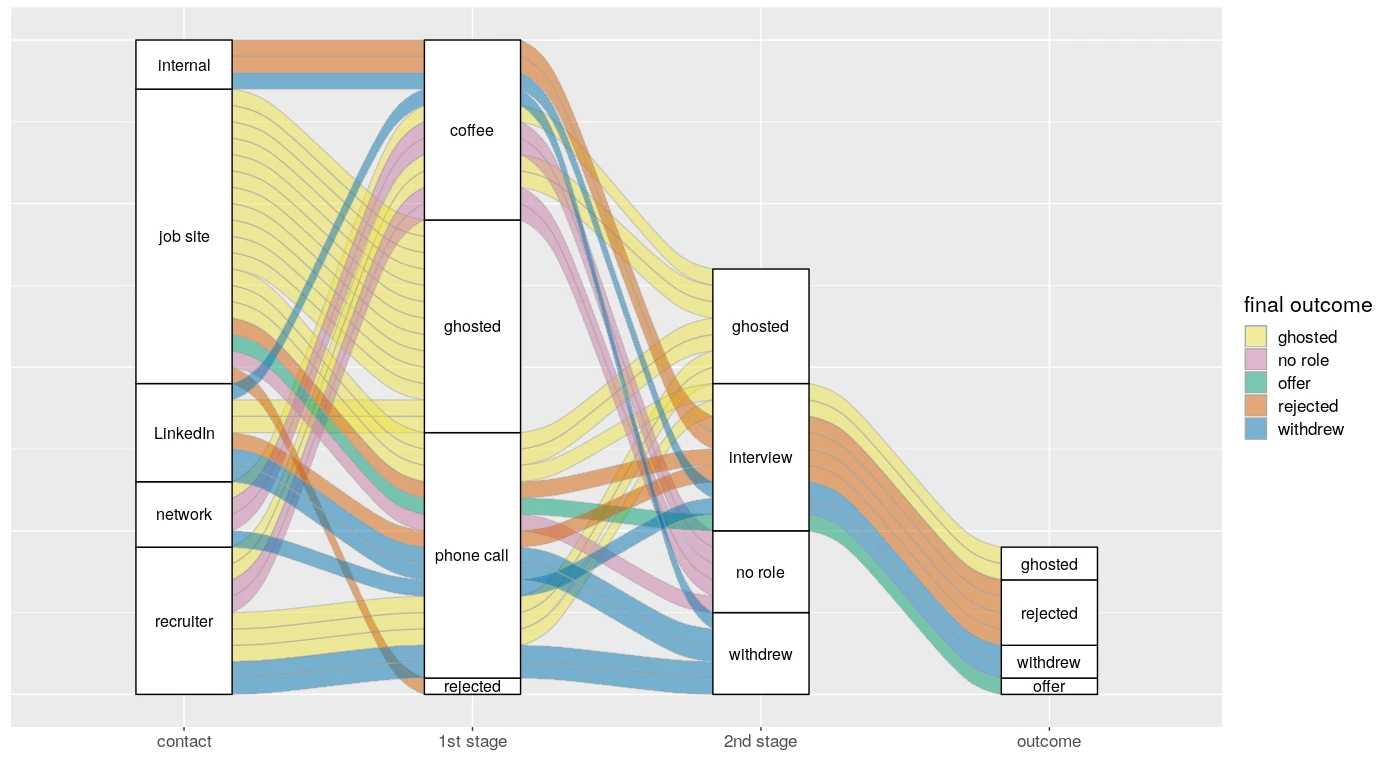
The alluvial graph
The graph at the top of this post is real data from my job hunt. You can track each application from its source to its outcome. “Ghosted” means that I received no response from the company. I strongly recommend some sort of tracking tool for your own job hunt—it’s therapeutic.
If you’d like to reproduce the graph above for your own job hunt, the code is below, and the (censored) data is available here.
library(tidyverse)
library(ggalluvial)
# Colours by Dr. Katie Lotterhos
# http://dr-k-lo.blogspot.com/2013/07/a-color-blind-friendly-palette-for-r.html
"job_outcomes.csv" %>%
read_csv %>%
mutate(final_outcome = coalesce(outcome, `2nd stage`, `1st stage`)) %>%
to_lodes(key = "contact", axes = 2:5) %>%
ggplot(aes(x = contact, stratum = stratum,
alluvium = alluvium, label = stratum)) +
geom_alluvium(aes(fill = final_outcome), color = "darkgrey", na.rm = TRUE) +
geom_stratum(na.rm = TRUE) +
geom_text(stat = "stratum", na.rm = TRUE, size = 12 * 0.352778) + # convert pt to mm
theme(
axis.text.y = element_blank(),
axis.ticks.y = element_blank(),
text = element_text(size = 16)
) +
xlab(NULL) +
labs(fill = "final outcome") + # legend title
scale_fill_manual(values = c(
"ghosted" = "#F0E442",
"no role" = "#CC79A7",
"withdrew" = "#0072B2",
"rejected" = "#D55E00",
"offer" = "#009E73"
)) devtools::session_info()
#> ─ Session info ───────────────────────────────────────────────────────────────
#> setting value
#> version R version 4.0.0 (2020-04-24)
#> os Ubuntu 20.04 LTS
#> system x86_64, linux-gnu
#> ui X11
#> language en_AU:en
#> collate en_AU.UTF-8
#> ctype en_AU.UTF-8
#> tz Australia/Melbourne
#> date 2020-06-13
#>
#> ─ Packages ───────────────────────────────────────────────────────────────────
#> package * version date lib source
#> assertthat 0.2.1 2019-03-21 [1] CRAN (R 4.0.0)
#> backports 1.1.7 2020-05-13 [1] CRAN (R 4.0.0)
#> callr 3.4.3 2020-03-28 [1] CRAN (R 4.0.0)
#> cli 2.0.2 2020-02-28 [1] CRAN (R 4.0.0)
#> crayon 1.3.4 2017-09-16 [1] CRAN (R 4.0.0)
#> desc 1.2.0 2018-05-01 [1] CRAN (R 4.0.0)
#> devtools 2.3.0 2020-04-10 [1] CRAN (R 4.0.0)
#> digest 0.6.25 2020-02-23 [1] CRAN (R 4.0.0)
#> downlit 0.0.0.9000 2020-06-12 [1] Github (r-lib/downlit@87fb1af)
#> ellipsis 0.3.1 2020-05-15 [1] CRAN (R 4.0.0)
#> evaluate 0.14 2019-05-28 [1] CRAN (R 4.0.0)
#> fansi 0.4.1 2020-01-08 [1] CRAN (R 4.0.0)
#> fs 1.4.1 2020-04-04 [1] CRAN (R 4.0.0)
#> glue 1.4.1 2020-05-13 [1] CRAN (R 4.0.0)
#> htmltools 0.4.0 2019-10-04 [1] CRAN (R 4.0.0)
#> hugodown 0.0.0.9000 2020-06-12 [1] Github (r-lib/hugodown@6812ada)
#> knitr 1.28 2020-02-06 [1] CRAN (R 4.0.0)
#> magrittr 1.5 2014-11-22 [1] CRAN (R 4.0.0)
#> memoise 1.1.0.9000 2020-05-09 [1] Github (hadley/memoise@4aefd9f)
#> pkgbuild 1.0.7 2020-04-25 [1] CRAN (R 4.0.0)
#> pkgload 1.0.2 2018-10-29 [1] CRAN (R 4.0.0)
#> prettyunits 1.1.1 2020-01-24 [1] CRAN (R 4.0.0)
#> processx 3.4.2 2020-02-09 [1] CRAN (R 4.0.0)
#> ps 1.3.3 2020-05-08 [1] CRAN (R 4.0.0)
#> R6 2.4.1 2019-11-12 [1] CRAN (R 4.0.0)
#> Rcpp 1.0.4.6 2020-04-09 [1] CRAN (R 4.0.0)
#> remotes 2.1.1 2020-02-15 [1] CRAN (R 4.0.0)
#> rlang 0.4.6 2020-05-02 [1] CRAN (R 4.0.0)
#> rmarkdown 2.2.3 2020-06-12 [1] Github (rstudio/rmarkdown@4ee96c8)
#> rprojroot 1.3-2 2018-01-03 [1] CRAN (R 4.0.0)
#> sessioninfo 1.1.1 2018-11-05 [1] CRAN (R 4.0.0)
#> stringi 1.4.6 2020-02-17 [1] CRAN (R 4.0.0)
#> stringr 1.4.0 2019-02-10 [1] CRAN (R 4.0.0)
#> testthat 2.3.2 2020-03-02 [1] CRAN (R 4.0.0)
#> usethis 1.6.1 2020-04-29 [1] CRAN (R 4.0.0)
#> withr 2.2.0 2020-04-20 [1] CRAN (R 4.0.0)
#> xfun 0.14 2020-05-20 [1] CRAN (R 4.0.0)
#> yaml 2.2.1 2020-02-01 [1] CRAN (R 4.0.0)
#>
#> [1] /home/mdneuzerling/R/x86_64-pc-linux-gnu-library/4.0
#> [2] /usr/local/lib/R/site-library
#> [3] /usr/lib/R/site-library
#> [4] /usr/lib/R/library