I’m house-hunting, and while I’d love to buy a 5-bedroom house with a pool 10 minutes walk from Flinders Street Station I probably can’t afford that. So I need to take a broader look at Melbourne.
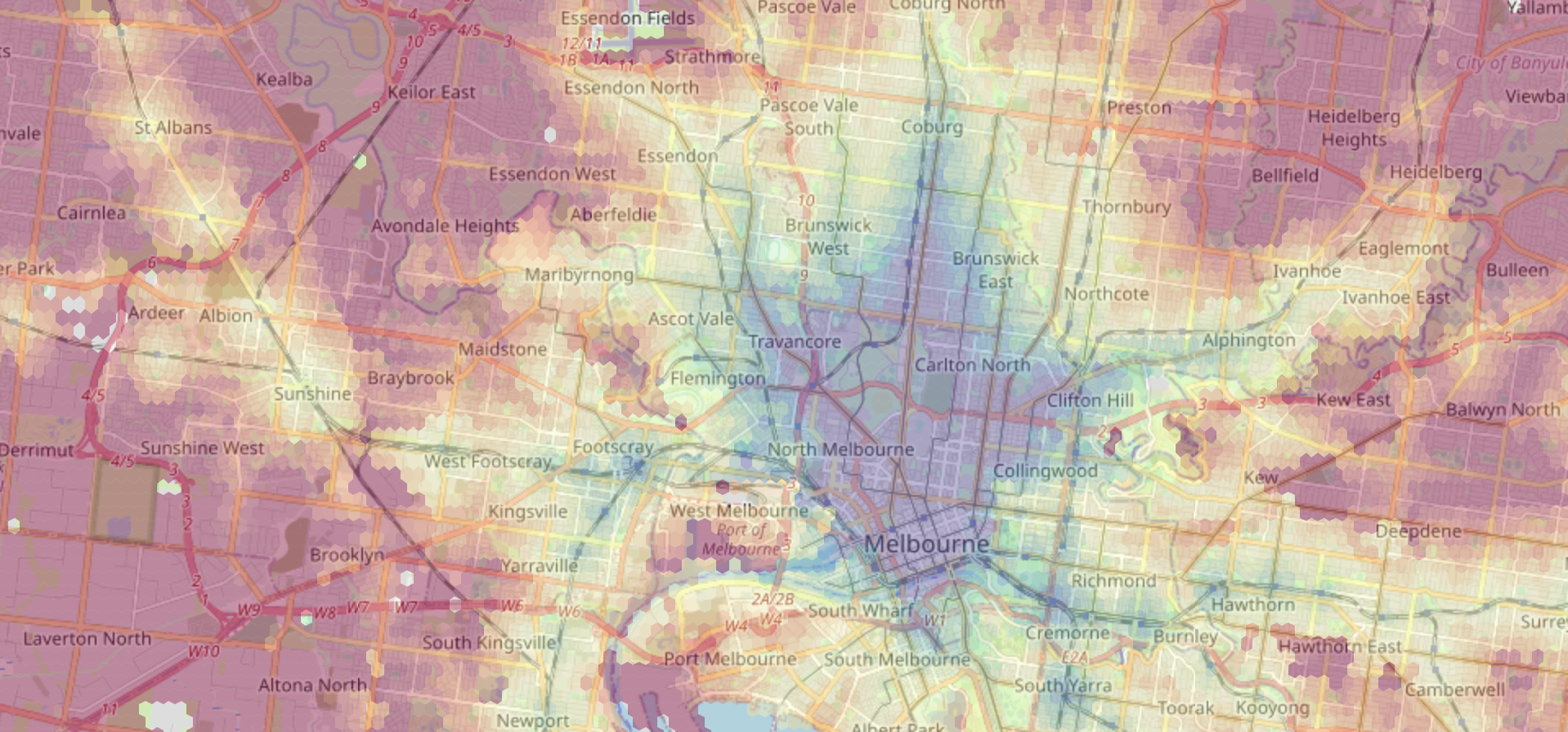
One of the main constraints is commute time. I built a choropleth of commute times to the University of Melbourne and put it on top of a map of Melbourne.
The rough idea is to create a fine hexagonal grid across the city using the sf package, and then to pass the centre of each hexagon through the Google Maps Directions Matrix API with the help of the (Melbourne-made) googleway package.
I’ve been playing around with an idea for a new R package. I call it exemplar and here’s how it works: I provide an example of what data should look like — an exemplar. The package gives a function that checks to make sure that any new data looks the same. The generated function checks — for each column — duplicate values, missing values, ranges, and more.
The validation function doesn’t have any dependencies at all.
When I train a machine learning model in a blog post, I edit out all the mistakes. I make it seem like I had the perfect data I needed from the very start, and I never add a useless feature. This time, I want to train a model with all the mistakes and fruitless efforts included.
My goal here is to describe my process of creating a model rather than just presenting the final code.
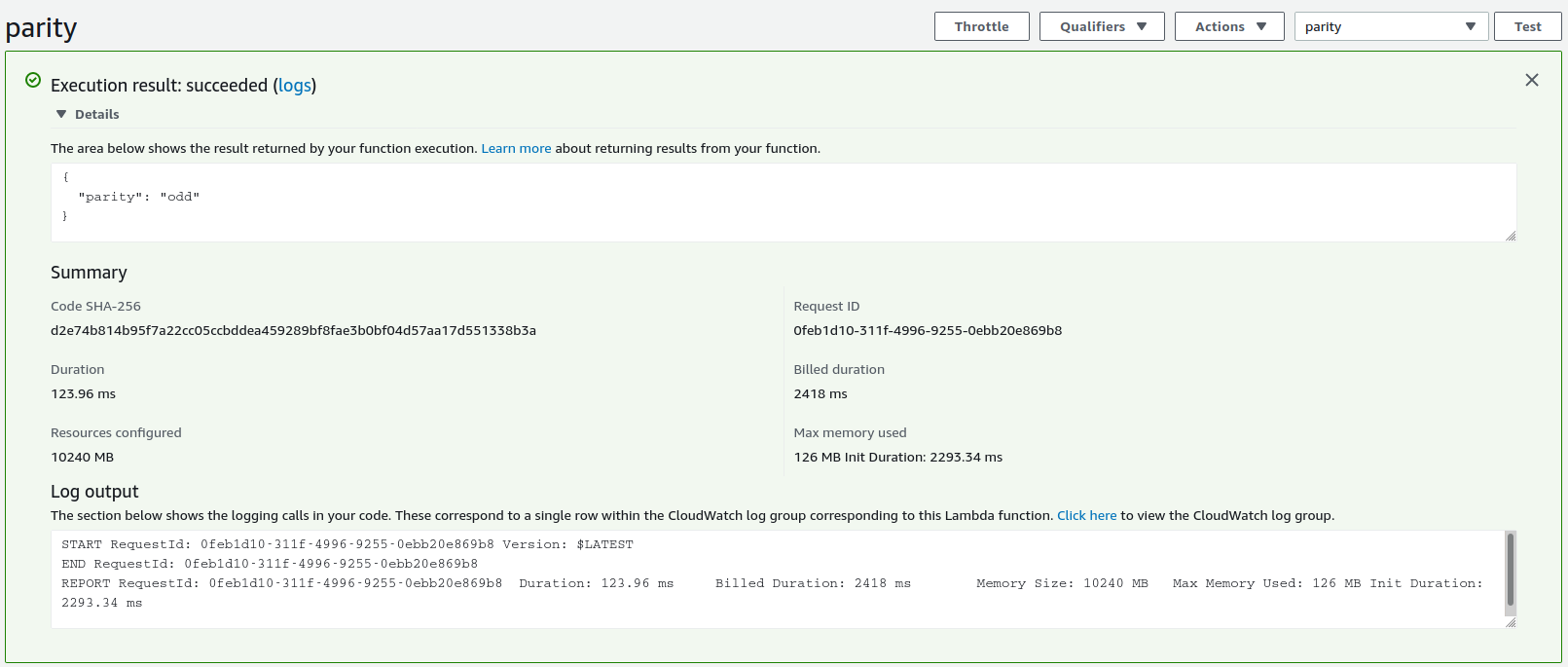
I have a URL with a colour parameter, like “https://example.com/diamonds?colour=H”. When I go to this URL in my browser, an AWS Lambda instance takes that parameter and passes it to rmarkdown::render, which knits a customised R Markdown report. My Lambda returns the knitted report as HTML, which my browser displays. If I change the parameter to “colour=G”, I get a different report, knitted on-demand.
This is all serverless, so I only pay each time a report is requested (around $0.
Metaflow is one of my favourite R packages. Actually, it’s a Python module, but the R package provides a set of bindings for running R code through Metaflow. Recently I’ve spent a good amount of effort trying to improve the way that R data is translated to the Python side of Metaflow, but I just can’t get it to work.
So I thought I’d post about what I’ve learnt. Maybe someone will have an answer.
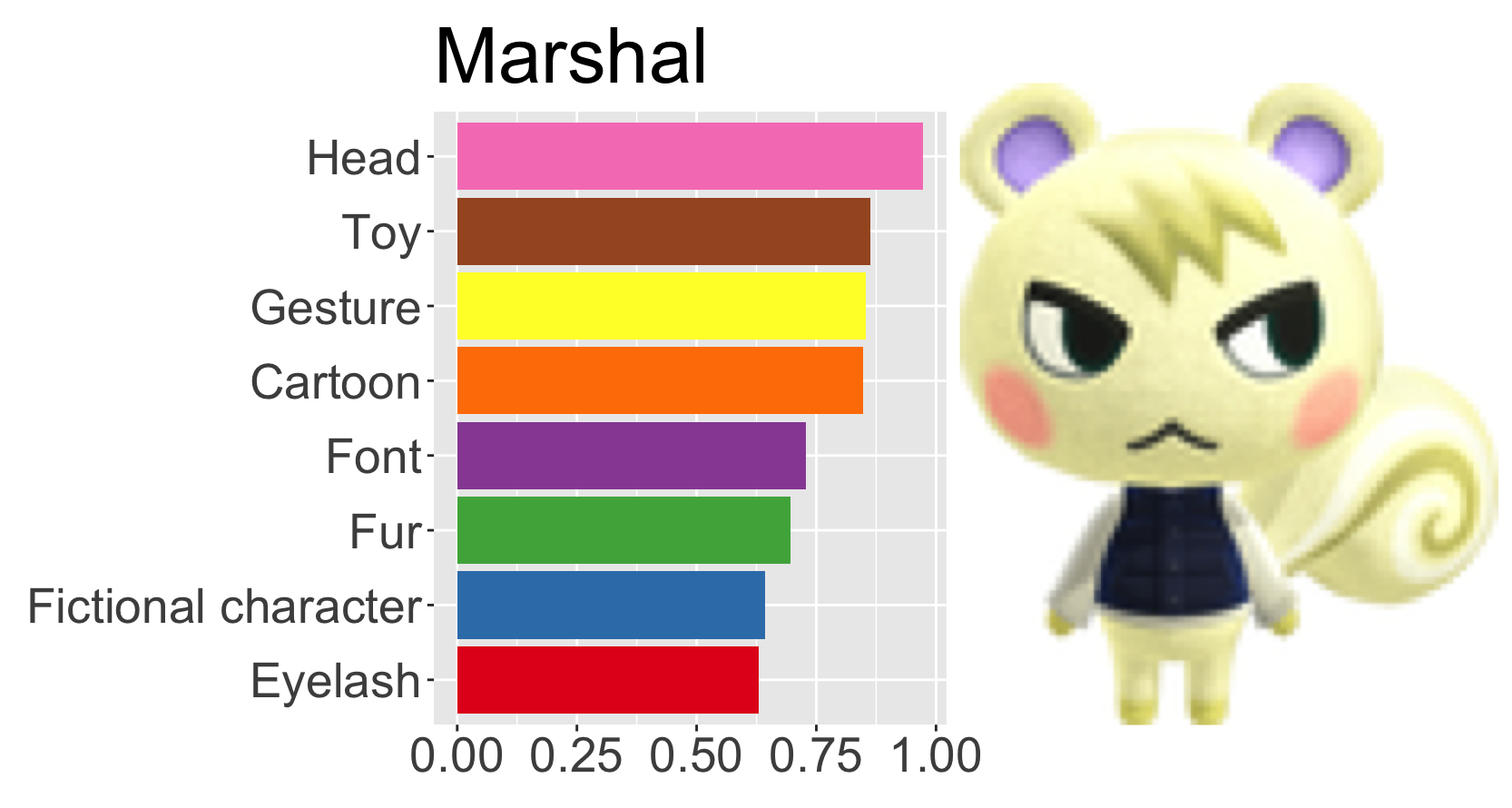
Animal Crossing: New Horizons kept me sane throughout the first Melbourne COVID lockdown. Now, in lockdown 4, it seems right that I should look back at this cheerful, relaxing game and do some data stuff. I’m going to take the Animal Crossing villagers in the Tidy Tuesday Animal Crossing dataset and combine it with survey data from the Animal Crossing Portal, giving each villager a measure of popularity. I’ll use the Google Cloud Vision API to annotate each of the villager thumbnails, and with these train a a (pretty poor) model of villager popularity.
I went down a strange path recently, trying to compile binaries of R packages for Linux. I’m not sure why — this area is pretty much covered by the RStudio Package Manager. I’ll leave my Dockerfiles here in case they’re of any use to a future wayward R programmer.
The intention here is to build a Docker image that can build an R binary with the below command. I’m trying to build x86 binaries on my ARM Macbook, so I’m specifying the platform during both build and run.
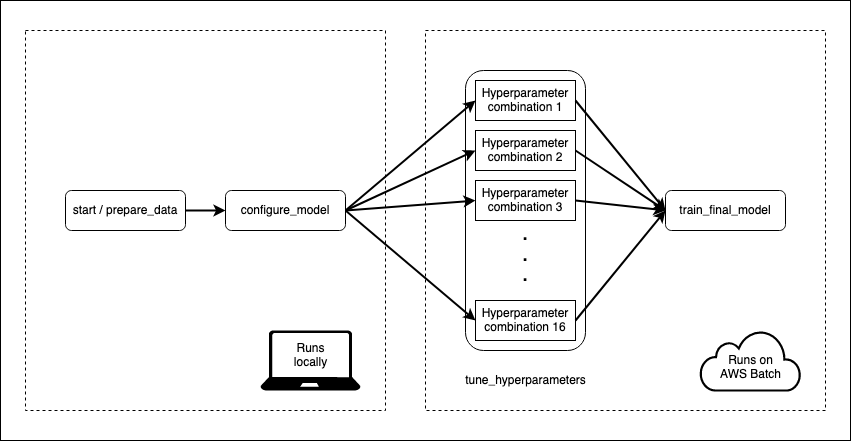
I have a machine learning model that takes some time to train. Data pre-processing and model fitting can take 15–20 minutes. That’s not so bad, but I also want to tune my model to make sure I’m using the best hyper-parameters. With 16 different combinations of hyperparameters and 5-fold cross-validation, my 20 minutes can become a day or more.
Metaflow is an open-source tool from the folks at Netflix that can be used to make this process less painful.
AWS has announced support for container images for their serverless computing platform Lambda. AWS doesn’t provide an R runtime for Lambda, and this was the excuse I needed to finally try to make one.
An R runtime means that I can take advantage of AWS Lambda to put my R functions in the cloud. I don’t have to worry about provisioning servers or spinning up containers — the function itself is the star.
Locking down R package dependencies and versions is a solved problem, thanks to the easy-to-use renv package. System dependencies — those Linux packages that need to be installed to make certain R packages work — are a bit harder to manage.
Option 1: Hard-coding The easiest option is to hard-code the system dependencies. I did this recently when I was creating a Dockerfile for a very simple Plumber API:
RUN apt-get update -qq && apt-get -y --no-install-recommends install \ make \ libsodium-dev \ libicu-dev \ libcurl4-openssl-dev \ libssl-dev My Dockerfile used only three R packages and so its system dependencies were not complicated.