When I train a machine learning model in a blog post, I edit out all the mistakes. I make it seem like I had the perfect data I needed from the very start, and I never add a useless feature. This time, I want to train a model with all the mistakes and fruitless efforts included.
My goal here is to describe my process of creating a model rather than just presenting the final code.
The material in this post is adapted from a presentation I gave to the Deakin Girl Geeks student society of Deakin University.
One of my favourite datasets: Pokémon
This Pokémon data comes from a gist prepared by GitHub user simsketch. I manually corrected the last few rows as suggested in the comments/
library(tidyverse)
pokemon <- read_csv("data/pokemon.csv") %>%
janitor::clean_names() %>%
mutate(
type1 = as.factor(type1),
type2 = as.factor(type2),
legendary = as.logical(legendary)
)
pokemon %>% colnames
#> [1] "number" "code" "serial" "name"
#> [5] "type1" "type2" "color" "ability1"
#> [9] "ability2" "ability_hidden" "generation" "legendary"
#> [13] "mega_evolution" "height" "weight" "hp"
#> [17] "atk" "def" "sp_atk" "sp_def"
#> [21] "spd" "total"Pokémon have types describing the elements or categories with which they are most closely affiliated. Charmander, for example, is a lizard with a perpetual flame on its tail and so is a Fire Pokémon. There are 18 types in total.
Pokémon also have stats — attributes that describe their strengths and weaknesses. These are usually abbreviated:
- hp: hit points, a numerical representation of how much health the Pokémon has
- atk: determines how much physical damage the Pokémon can deal
- sp. atk: determines how much special damage the Pokémon can deal. Some abilities (or moves) are more supernatural in nature, like a breath of fire or a bolt of thunder, and so are considered special.
- def: defence, a Pokémon’s capacity to resist physical damage.
- sp. def: special defence, a Pokémon’s capacity to resist special damage.
- spd: speed, how quickly a Pokémon can attack.
It makes sense then that a Fighting-type Pokémon might have stronger atk than a Fire-type Pokémon, whose moves are more likely to be special. The question is: from a Pokémon’s stats or other features, can we determine its type?
The advanced technique of actually looking at the data
I’m not proud of this, but I often find myself writing many lines of exploratory code before I actually look at the data. Due to its rarity, I call this an advanced technique.
Now that I have a question I’m trying to answer, the first step is to look at the data.
pokemon %>%
select(number, name, type1, type2, hp:total, color) %>%
head() %>%
knitr::kable("html")
| number | name | type1 | type2 | hp | atk | def | sp_atk | sp_def | spd | total | color |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Bulbasaur | Grass | Poison | 45 | 49 | 49 | 65 | 65 | 45 | 318 | Green |
| 2 | Ivysaur | Grass | Poison | 60 | 62 | 63 | 80 | 80 | 60 | 405 | Green |
| 3 | Venusaur | Grass | Poison | 80 | 82 | 83 | 100 | 100 | 80 | 525 | Green |
| 3 | Mega Venusaur | Grass | Poison | 80 | 100 | 123 | 122 | 120 | 80 | 625 | Green |
| 4 | Charmander | Fire | NA | 39 | 52 | 43 | 60 | 50 | 65 | 309 | Red |
| 5 | Charmeleon | Fire | NA | 58 | 64 | 58 | 80 | 65 | 80 | 405 | Red |
Always ask: what does one row of the data represent?
This is incredibly important — if I don’t know what one row of the data is, I can’t progress any further. Those with database experience might ask a related question: what is the primary key?
A reasonable assumption is that every row is a Pokémon, and this would be wrong.
The Pokémon number seems like a good candidate here, but I can see that Venusaur and Mega Venusaur share a number. A mega evolution is a temporary transformation of a Pokémon. It seems that in the data I have here (and in the Pokémon universe more generally), mega evolutions are seen as variations of existing Pokémon.
The question that follows is whether I should include these mega evolutions or discard them. I’m going to keep them for now, since I think they’re still relevant to the hypothesis.
I might then ask if name is a unique identifier, but this turns out to be false:
pokemon %>%
filter(name == "Darmanitan") %>%
select(number, name, type1, type2, hp:total, color) %>%
knitr::kable("html")
| number | name | type1 | type2 | hp | atk | def | sp_atk | sp_def | spd | total | color |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 555 | Darmanitan | Fire | NA | 105 | 140 | 55 | 30 | 55 | 95 | 480 | Red |
| 555 | Darmanitan | Fire | Psychic | 105 | 30 | 105 | 140 | 105 | 55 | 540 | White |
| 555 | Darmanitan | Ice | NA | 105 | 140 | 55 | 30 | 55 | 95 | 480 | White |
| 555 | Darmanitan | Ice | Fire | 105 | 160 | 55 | 30 | 55 | 135 | 540 | White |
This happens because Darmanitan has multiple forms. Some of these have different stats, but some have identical stats and different types. A natural question might be if name, types, and stats are enough to make each row unique. This is wrong:
pokemon %>%
filter(name == "Burmy") %>%
select(number, name, type1, type2, hp:total, color) %>%
knitr::kable("html")
| number | name | type1 | type2 | hp | atk | def | sp_atk | sp_def | spd | total | color |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 412 | Burmy | Bug | NA | 40 | 29 | 45 | 29 | 45 | 36 | 224 | Green |
| 412 | Burmy | Bug | NA | 40 | 29 | 45 | 29 | 45 | 36 | 224 | Brown |
| 412 | Burmy | Bug | NA | 40 | 29 | 45 | 29 | 45 | 36 | 224 | Red |
These forms usually have a different appearance, hence the difference in colour for these entries for Burmy. Indeed, this turns out to be the explanation I’m looking for. This has to be verified manually, by using the janitor::get_dupes function to investigate the dupes and looking up the Pokémon on Bulbapedia.
I’ll keep all of these rows as. Different forms of the same Pokémon can sometimes have different stats so it makes sense to treat each form as a separate Pokémon.
Missing data and consistency
I want to take another look at the data now to consider any missing values, and if there are any obvious errors in the values.
| number | name | type1 | type2 | hp | atk | def | sp_atk | sp_def | spd | total | color |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Bulbasaur | Grass | Poison | 45 | 49 | 49 | 65 | 65 | 45 | 318 | Green |
| 2 | Ivysaur | Grass | Poison | 60 | 62 | 63 | 80 | 80 | 60 | 405 | Green |
| 3 | Venusaur | Grass | Poison | 80 | 82 | 83 | 100 | 100 | 80 | 525 | Green |
| 3 | Mega Venusaur | Grass | Poison | 80 | 100 | 123 | 122 | 120 | 80 | 625 | Green |
| 4 | Charmander | Fire | NA | 39 | 52 | 43 | 60 | 50 | 65 | 309 | Red |
| 5 | Charmeleon | Fire | NA | 58 | 64 | 58 | 80 | 65 | 80 | 405 | Red |
There are two things I notice here:
type2can be missing, buttype1appears to be present all the time (based on this very small sample). Are there any Pokémon without a type at all?- There’s a
totalvalue, which I assume is the sum of all six stats. Is my assumption correct?
Validating data assumptions makes me feel safer
I’ll implement a quick function to validate this data, answering my two questions above.
validate_pokemon <- function(pokemon_data) {
total_mismatch <- with(
pokemon_data,
total != hp + atk + def + sp_atk + sp_def + spd
)
important_columns <- pokemon_data %>% select(type1, hp:atk)
!any(total_mismatch) && !any(is.na(important_columns))
}
validate_pokemon(pokemon)
#> [1] TRUELooks good! In a “real” situation I would go into much more detail, looking for as many potential problems as I can think of (for example, is color always present?). But combining all that logic into a single validation function is a good step, because I can insert this into any pipelines as a necessary step.
Plot the data. Always.
Exploratory Data Analysis is about getting comfortable with the data. There’s no algorithm for it. While I’m making only two graphs here, in a “real” situation this would be dozens of graphs (each with multiple failed attempts).
Does more stats mean more powerful?
I’ll consider the total stat amount, and determine if it actually does represent a Pokémon’s strength. Certain Pokémon are considered “legendary” — rare and more powerful than the average Pokémon. It makes sense that legendary Pokémon would have, on average, a higher total stat. And sure enough:
pokemon %>%
ggplot(
aes(
x = total,
color = legendary
)
) +
geom_density(size = 1) +
xlab("Total stats") +
theme(
axis.text.y = element_blank(),
axis.ticks.y = element_blank(),
legend.position = "top"
)
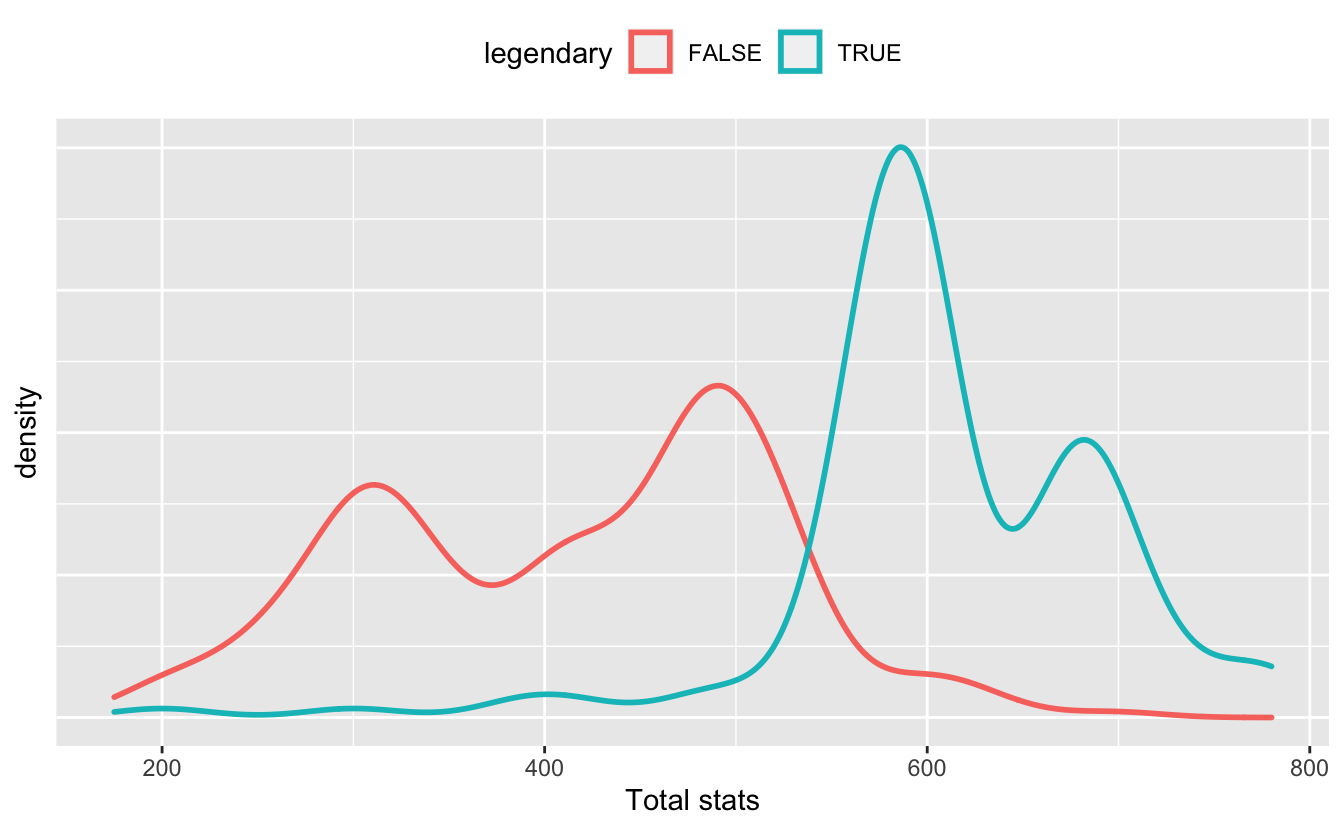
Sure enough, more stats means more powerful.
Does the hypothesis make sense?
If my hypothesis is that stats matter to predict type, I should be able to plot something to show that this makes sense. I’m not looking for incontrovertible proof here. But if I can’t find something, I may as well stop here.
Hypotheses don’t come out of no where. Somewhere there’s a anecdote or a feeling that a relationship exists before it’s been formally investigated. In businesses that often comes from a domain expert — someone who isn’t necessarily an expert on data, but who knows the domain of the data better than any data scientist.
In this case, I’ve played enough Pokémon to know that Fire Pokémon tend to favour special attack and Fighting Pokémon favour (physical) attack.
pokemon %>%
filter(
type1 %in% c(
"Fire", "Fighting"
)
) %>%
ggplot(aes(
x = atk,
y = sp_atk,
color = type1
)) +
geom_point(size = 2) +
scale_color_manual(
values = c(
"Fire" = "#F8766D",
"Fighting" = "#00BFC4"
)
)
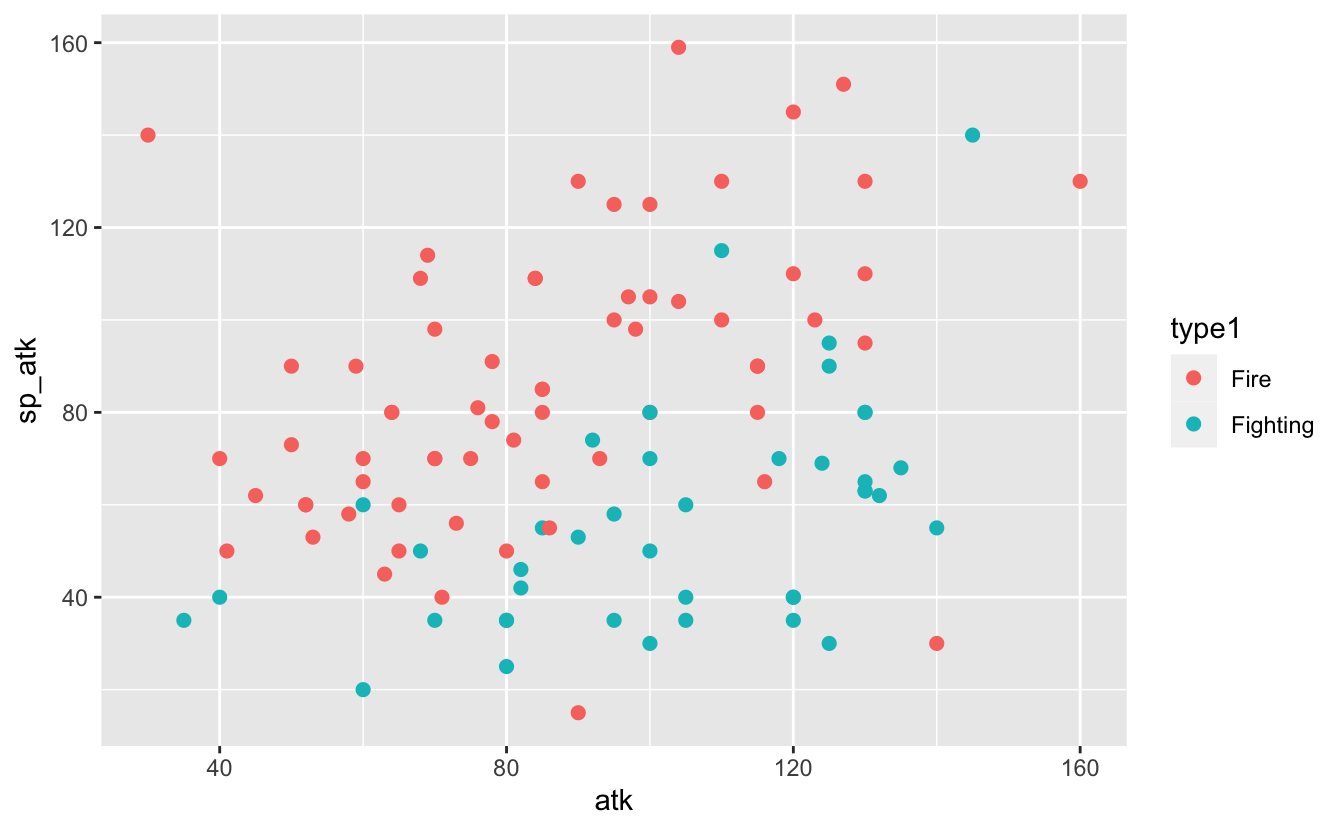
There’s a nice separation here that strongly suggests that — for these two types, at least — it’s possible to use a Pokémon’s stats to guess its primary type. I imagine drawing a in between the two groups as best I can, noting that there’s no way to perfectly separate them. Depending on which side of the line the stats of a particular Pokémon falls I can classify it as either Fire or Fighting.
Recap: What do I know?
I haven’t given much thought to modelling yet. I’ve identified a question based on the data’s domain, and then I explored the data by asking questions and validating assumptions. Modelling comes into the process late.
Here’s what I know so far:
- Pokémon have one or two types — the primary (first) type is never missing
- None of the stats are missing
totalstats is a good measure of a Pokémon’s strength- There’s some relationship between primary type and stats
It’s not time to model just yet. First I need to…
Define a target metric
Before I start training any models, I need to know the target metric under which they’ll be evaluated.
This question is impossible to answer here; my model is never going to be used for anything, so the choice of target metric can’t be judged. So I’ll keep it simple: under a candidate model, what percentage of type predictions are correct?
In a “real” situation, I would have other concerns. I would be asking about what happens when I get the prediction wrong, and what the benefits are when I get it right. These questions have no meaning here (there is no cost and no benefit to a model that is never put into practice), but they’re crucial in real-life data science.
For example, consider a model that predicts the probability that it will rain. If I predict rain and get it wrong, I leave the house carrying an umbrella that I don’t need — no big deal. If I get it right, I get to keep my clothes dry. The cost of a false positive is small and the benefits of a true positive are high, so I might undervalue false negatives (by, say, carrying an umbrella at a 25% chance of rain instead of a 50% chance of rain).
What makes a model good enough?
Now that I have my target metric, I need to know what counts as a good enough model. There’s never a situation in which I have unlimited time to train the perfect model — if nothing else, I’d get bored eventually. I need a stopping criterion.
Sometimes this is defined by the problem itself. For example, I might be required to demonstrate a certain financial benefit. Or I might have a time constraint and so I need to base my decisions on the best model I’m able to train in a given time.
Otherwise, for classification problems, I find it helps to consider a naive algorithm which predicts the most common class every time. The proportion of the most common class is also known as the no-information rate.
I need to calculate this rate after I split my data, and base it on the training data alone. This prevents me from making judgments based on the test data, and lets me compare my model’s performance to the no-information rate of the data it was trained on.
The following function will calculate the no-information rate. The most common type is almost always Water, but this function doesn’t assume that.
no_information_rate <- function(pokemon_data) {
pokemon_data %>%
count(type1) %>%
mutate(proportion = n / sum(n)) %>%
top_n(1, proportion) %>%
pull(proportion)
}I should aim to beat this metric (preferably by a few percent) to be be convinced that my model has actually learnt something.
There are other criteria I need to pay attention too, though. I want to make sure that my predictions aren’t concentrated on only one or two types. But with 18 types and 1048 rows, this may be tough. At some point I need to confront the problem I’ve been ignoring up until now: the number of classes is very small compared to the number of data points!
Let’s train a model!
Now I’ve done enough foundational work that I can train a model. I’m going to use the tidymodels meta-package, a favourite of mine:
I love random forests so that’s what I’ll use. A “proper” approach here would be to use a technique like cross-validation or train-validate-test split to compare multiple models, including multiple hyperparameter configurations for each model type. But I’m glossing over that for this post.
First, a simple train-test split. I’ll train my model on pokemon_train and validate it on pokemon_test.
set.seed(12345)
pokemon_split <- initial_split(pokemon, strata = "type1", prop = 0.7)
pokemon_train <- training(pokemon_split)
pokemon_test <- testing(pokemon_split)
nrow(pokemon_train)
#> [1] 733
nrow(pokemon_test)
#> [1] 315I now have a training set with 733 rows and a test set with 315 rows. I can use the function I prepared earlier to calculate the no-information rate.
no_information_rate(pokemon_train)
#> [1] 0.1323329This serves as a benchmark for my model. Here’s the definition of the model, created with the parsnip package:
pokemon_model <- rand_forest(
trees = 200,
mtry = 3
) %>%
set_engine("ranger") %>%
set_mode("classification")
pokemon_model
#> Random Forest Model Specification (classification)
#>
#> Main Arguments:
#> mtry = 3
#> trees = 200
#>
#> Computational engine: rangerAt this point the model hasn’t been fitted, so I had better fit it.
First attempt - a failure that looks like a success
Data science is a string of failures and hopefully (but not always) a successful result. But I have to start with a model so that I can iterate. So I’ll fit my model and see how it performs:
fitted_pokemon_model <- pokemon_model %>% fit(
type1 ~ hp + atk + def + sp_atk + sp_def + spd,
data = pokemon_train
)
first_attempt_accuracy <- pokemon_test %>%
mutate(
predicted_type1 = predict(
fitted_pokemon_model,
pokemon_test
)$.pred_class
) %>%
accuracy(type1, predicted_type1) %>%
pull(.estimate)
first_attempt_accuracy
#> [1] 0.2031746What a great result! 20.3% accuracy is better than the no-information rate of 13.2%. I’m clearly a great data scientist, and I can finally stop feeling insecure about my abilities.
Except that’s not a good result
A little pessimism is a good thing, and a good model should be met with scepticism. Doubly so if the model is a first attempt.
Data leakage is a situation in which data from the test set influences the training set, and so the model gets a peak into the test data that it shouldn’t have. It can lead to overfitting, and it’s sometimes extraordinarily difficult to detect.
Do you remember when you trained your first stock market model and got 99% accuracy? You imagined your life on your private island? And then you realised (or someone told you) that you needed to split your data into into two time periods so that the model couldn’t see the future? That was data leakage causing over-fitting. There’s no judgment from me here — everyone has made this mistake, and most of us (myself included) continue to do so.
There are no time columns in my data; the source of the data leakage is more subtle than that. Pokémon belong to families. Charmander, upon reaching certain conditions, permanently changes into Charmeleon through a process known as evolution. Charmeleon eventually becomes Charizard. All three of these Pokémon belong to the “Charmander” family. It’s reasonable to assume that the relationship between stats is similar for Pokémon in the same family.
Is my model learning that certain stat values are associated with certain types? Or is it learning to identify which Pokémon belong to which family, and then assuming that they all have the same type? That might be a fine model, but it detracts from my hypothesis.
Finding new data:
My model doesn’t contain information on Pokémon families. This is very common part of data science — thinking I have all the data but then needing to find more. I used the table from the Pokémon fandom wiki to associate a “family” with each Pokémon. The logic for these joins and some other minor corrections is stored as a gist. The result is a CSV named “pokemon_with_families.csv”.
pokemon <- readr::read_csv("data/pokemon_with_families.csv") %>%
janitor::clean_names() %>%
mutate(
type1 = as.factor(type1),
type2 = as.factor(type2),
legendary = as.logical(legendary)
)
#> Rows: 1041 Columns: 14
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> chr (5): name, type1, type2, family, color
#> dbl (8): number, hp, atk, def, sp_atk, sp_def, spd, total
#> lgl (1): legendary
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Grouped train-test split
I’ll re-split the data, this time ensuring that if a Pokémon from a given family is in pokemon_train, then all Pokémon in that family are in pokemon_train, and similarly for pokemon_test:
set.seed(12345)
train_families <- pokemon %>% distinct(family) %>%
sample_frac(0.7) %>% pull(family)
pokemon_train <- pokemon %>% filter(family %in% train_families)
pokemon_test <- pokemon %>% filter(!(family %in% train_families))This is a new training data set, so I have a new no-information rate:
no_information_rate(pokemon_train)
#> [1] 0.14361I’ll try re-fitting the model on this newly split data:
fitted_pokemon_model <- pokemon_model %>% fit(
type1 ~ hp + atk + def + sp_atk + sp_def + spd,
data = pokemon_train
)
second_attempt_accuracy <- pokemon_test %>%
mutate(
predicted_type1 = predict(
fitted_pokemon_model,
pokemon_test
)$.pred_class
) %>%
accuracy(type1, predicted_type1) %>%
pull(.estimate)
second_attempt_accuracy
#> [1] 0.14184414.2% is not so impressive when the no-information rate is 14.4%. Data leakage can make a huge difference!
A little bit of feature engineering
Feature engineering is the process of refining existing features or creating new ones to improve the accuracy of a model. Informally, it lets models use features the way a human being might see them.
I know that some Pokémon types are stronger than others. For example, Dragon Pokémon tend to be stronger than bug Pokémon. I can see that in the comparison of their atk and sp_atk below:
plot_dragon_bug <- function(pokemon_data) {
pokemon_data %>%
filter(
type1 %in% c(
"Bug", "Dragon"
)
) %>%
ggplot(aes(
x = atk,
y = sp_atk,
color = type1
)) +
geom_point(size = 2) +
scale_color_manual(
values = c(
"Dragon" = "#C77CFF",
"Bug" = "#7CAE00"
)
)
}
pokemon %>% plot_dragon_bug()
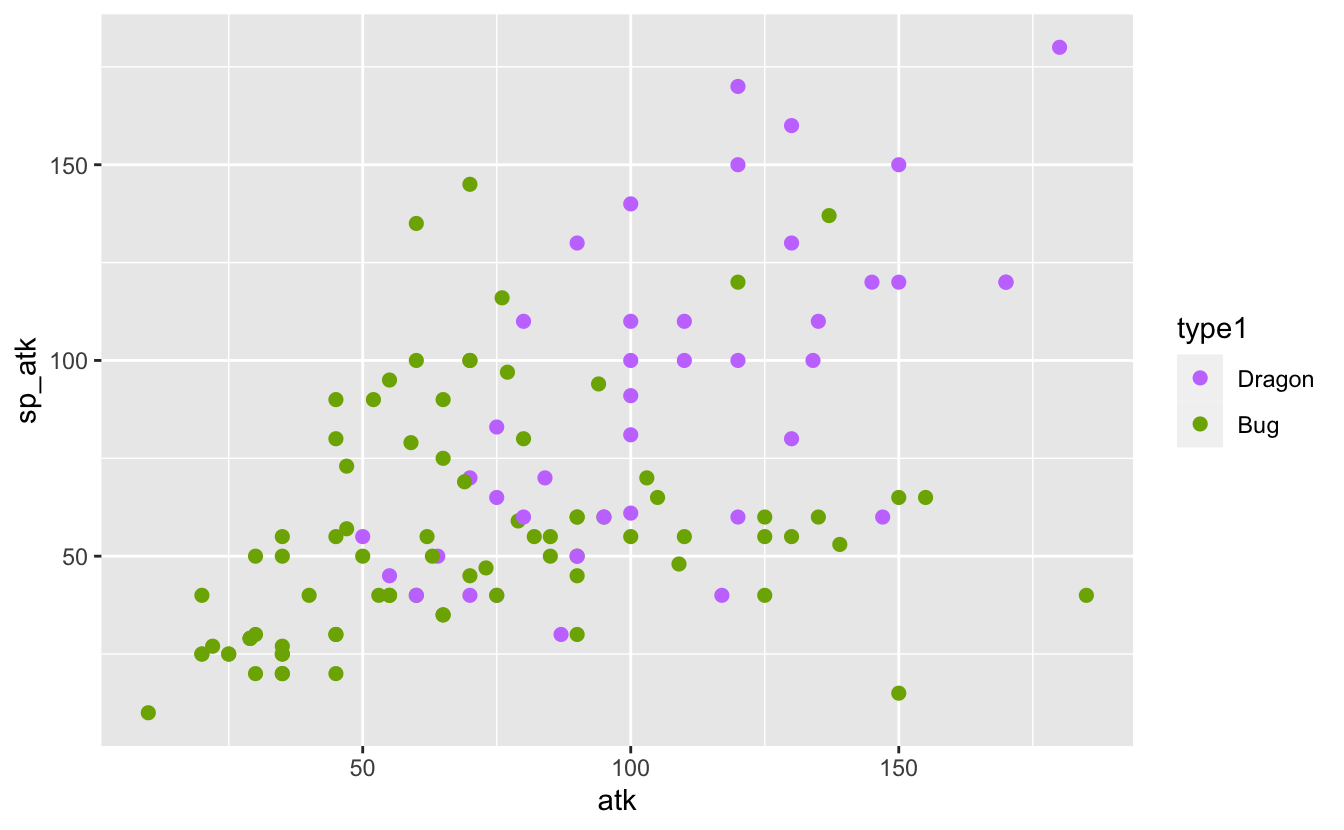
It’s possible that rather than considering absolute stats I need to consider proportional stats. That is, the proportion of attack, speed, etc. relative to a Pokémon’s total stats. If this helps to separate the types I might be able to see that separation in a plot:
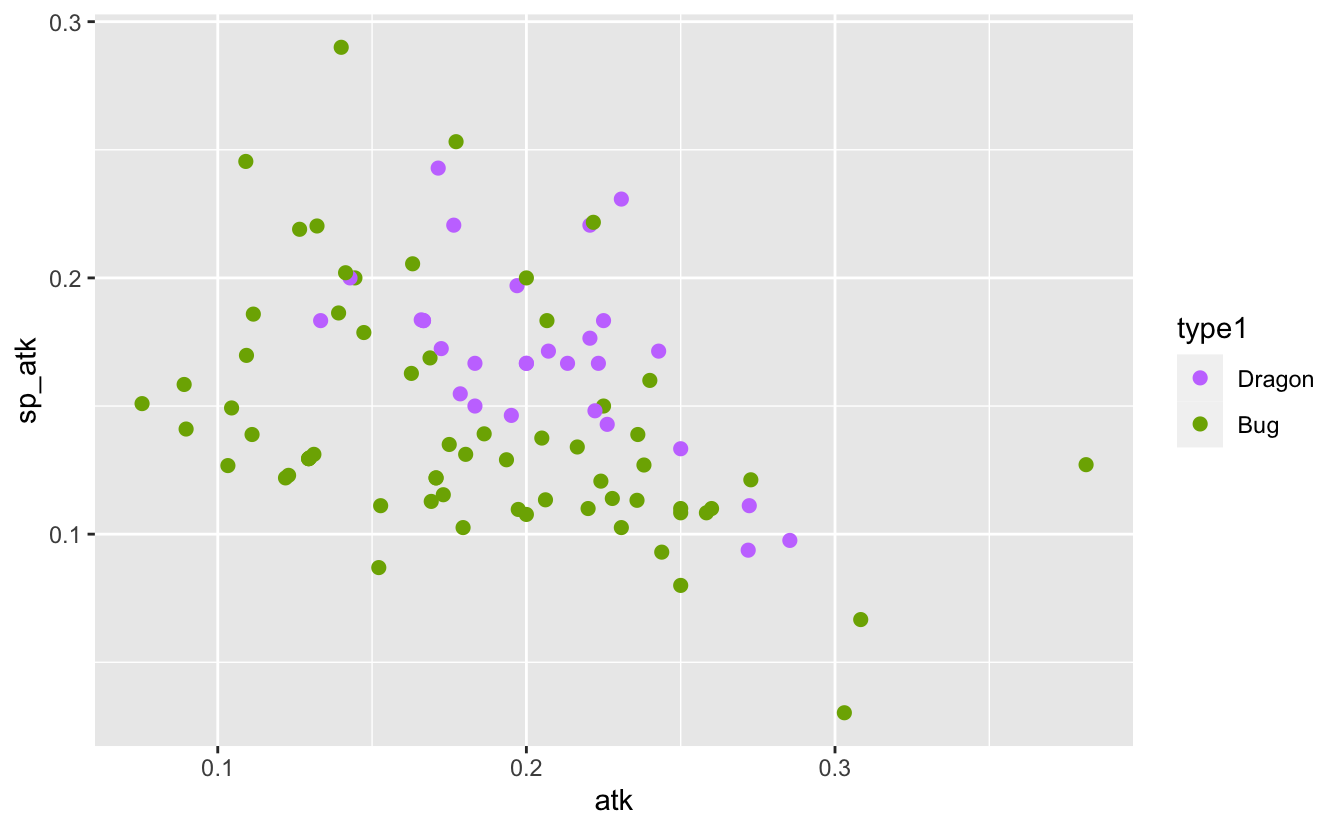
It’s not a very convincing change. If a difference is there, it’s a minor one. Still, I think it’s enough to proceed with another attempt a model.
I need to introduce a preprocessing recipe using the recipes package, part of the tidymodels universe. This recipe tells R how to manipulate my data before modelling. Recipes are prepared based on the training data and applied to the test data to prevent data leakage that might occur from steps such as imputation and normalisation.
preprocessing <- recipe(
type1 ~ hp + atk + def + sp_atk + sp_def + spd + total,
data = pokemon_train
) %>%
step_mutate(
hp = hp / total,
atk = atk / total,
def = def / total,
sp_atk = sp_atk / total,
sp_def = sp_def / total,
spd = spd / total
) %>%
step_normalize(total)The last step, which scales and centres the data, isn’t strictly necessary for tree-based models. It may, however, make it easier to interpret stats.
In tidymodels, a workflow is a combination of a model and a recipe. It lets me combine my preprocessing and modelling steps into a single object that can be fit in one step.
I can now see if this extra bit of feature engineering will pay off:
fitted_pokemon_workflow <- pokemon_workflow %>% fit(pokemon_train)
third_attempt_accuracy <- pokemon_test %>%
mutate(
predicted_type1 = predict(
fitted_pokemon_workflow,
pokemon_test
)$.pred_class
) %>%
accuracy(type1, predicted_type1) %>%
pull(.estimate)
third_attempt_accuracy
#> [1] 0.1347518That’s an accuracy of 13.5% compared to a no-information rate is 14.4%. That’s disappointing! It looks like this scaling didn’t do anything.
MORE DATA
At this point I’m willing to give up on my hypothesis. I don’t think that stats alone are enough to predict type. It may be a valid hypothesis for a smaller group of types, like Fire and Fighting, but the relationship doesn’t seem to be there for the whole data set.
Giving up on a hypothesis means getting to try new hypotheses. I want to try adding color. It shouldn’t come as a surprise that Grass Pokémon are often green and Fire Pokémon are often red. I’ll redefine my preprocessing recipe and workflow to include color (here given its unfortunate US spelling):
preprocessing <- recipe(
type1 ~ hp + atk + def + sp_atk + sp_def + spd + total + color,
data = pokemon_train
) %>%
step_mutate(
hp = hp / total,
atk = atk / total,
def = def / total,
sp_atk = sp_atk / total,
sp_def = sp_def / total,
spd = spd / total
) %>%
step_normalize(total)
pokemon_workflow <- workflow() %>%
add_recipe(preprocessing) %>%
add_model(pokemon_model)Hopefully this information, along with stats, should be enough to learn something about Pokémon types.
fitted_pokemon_workflow <- pokemon_workflow %>% fit(pokemon_train)
fourth_attempt_accuracy <- pokemon_test %>%
mutate(
predicted_type1 = predict(
fitted_pokemon_workflow,
pokemon_test
)$.pred_class
) %>%
accuracy(type1, predicted_type1) %>%
pull(.estimate)That’s an accuracy of 23.8% compared to a no-information rate is 14.4%. Finally, a result that isn’t terrible!
Dig into the results and ask questions
I’ve made another mistake: I’ve reduced my model performance to a single metric. It’s much more complicated than that. I need to gather some intuition about how my model performs, and a confusion matrix is a good visualisation for that:
pokemon_test %>%
mutate(
predicted = predict(
fitted_pokemon_workflow,
pokemon_test
)$.pred_class
) %>%
conf_mat(type1, predicted) %>%
autoplot(type = "heatmap") +
theme(
axis.text.x = element_text(
angle = 90,
vjust = 0.5,
hjust = 1
)
)
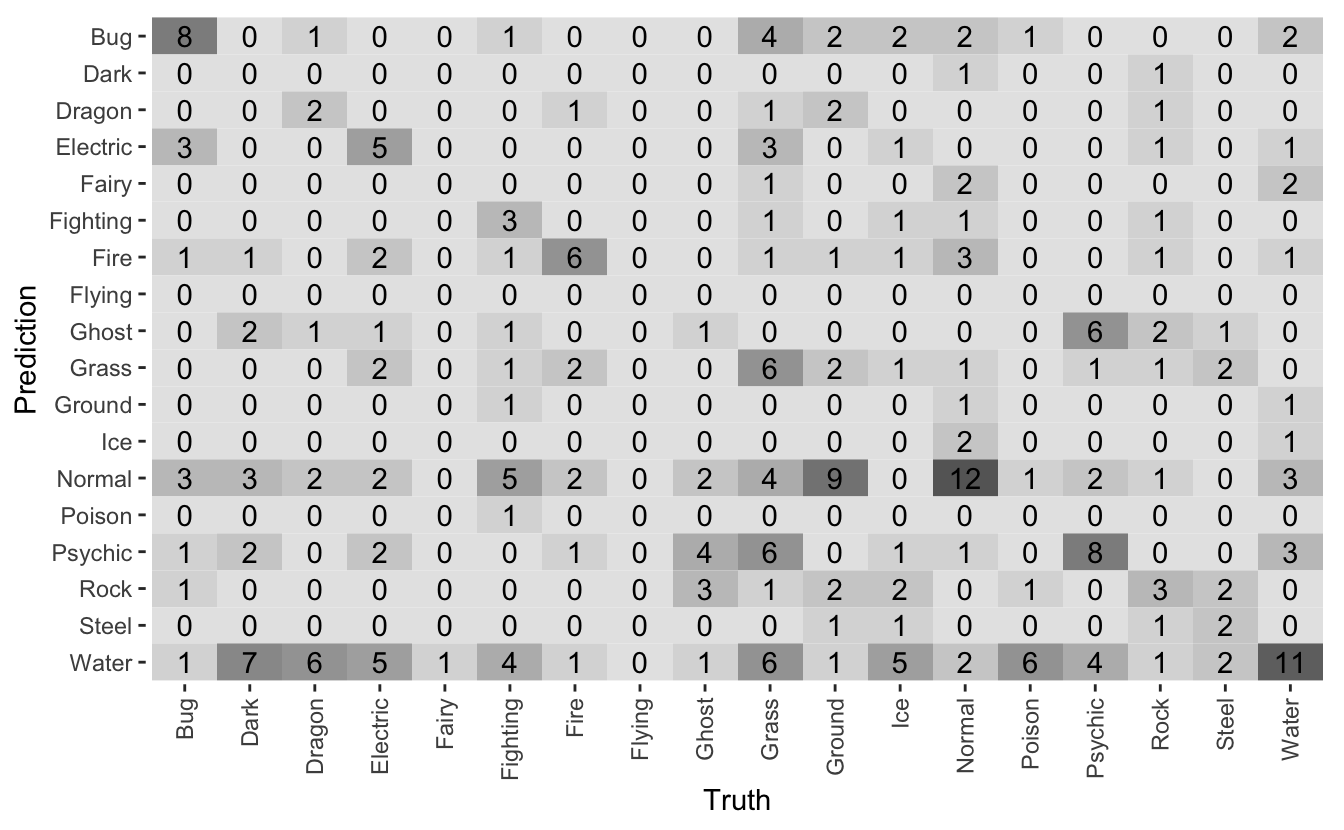
What I want to see is a lot of dark squares along the diagonal. The diagonal squares are the correct predictions, with everything else a misprediction.
The model seems to have learnt something about bug and psychic proble, so it’s not completely terrible. It’s making a lot of mistakes around Water and Normal Pokémon. These are the most common types, so it makes sense that the model would bias them and then get it wrong.
I can also see that some types are rare. For example, there are no Flying Pokémon in the test data! This is because many Flying Pokémon actually have Flying as their secondary type, and so there are very few example of primary Flying Pokémon.
Modelling strategy
What I’ve created here isn’t a useful model, because we already know the types of all the Pokémon. What I’ve outlined is a process for training a model. That process is:
- work out what you’re trying to answer
- look at your data
- define a metric
- decide what makes a model good enough
- split your data — watch out for data leakage!
- get more data if you need it
- train and evaluate — including visualisations!
And above all, recognise that data science is an iterative process in which success can only come after a long, disappointing chain of failures.
Bonus: vetiver, a new approach for deploying R models
Julia Silge of the tidymodels team recently announced a new package for model deployment in R: vetiver. I have a model here and it’s already a tidymodels workflow, so I thought this would be a good chance to quickly explore vetiver.
I’m going to need three more packages here: vetiver itself, the pins package for storing model artefacts, and plumber for hosting models as an API.
I’ve already got a workflow, so it’s straightforward to turn it into a vetiver model:
v <- vetiver_model(fitted_pokemon_workflow, "pokemon_rf")
v
#>
#> ── pokemon_rf ─ <butchered_workflow> model for deployment
#> A ranger classification modeling workflow using 8 featuresI’m going to host the model in a separate R process so that it can serve predictions to data in my current R process. For that I’ll need somewhere to save the model so that I can access it between separate R processes. The local board from the pins package is suitable. This is a storage location that’s local to my computer. If I wanted to save the model artefact to a particular location I would use board_folder instead, but in this case I don’t care where the model is saved.
board_local() %>% vetiver_pin_write(v)
#> Creating new version '20220124T201636Z-f3f19'
#> Writing to pin 'pokemon_rf'
#>
#> Create a Model Card for your published model
#> * Model Cards provide a framework for transparent, responsible reporting
#> * Use the vetiver `.Rmd` template as a place to start
#> This message is displayed once per session.I create the start_plumber function that loads the necessary packages and the model artefact, and starts serving it as an API using the plumber package. A heads up here that I’m being quite eager to load massive metapackages like tidyverse and tidymodels. This is generally a bad idea in production situations. If I were doing this “for real” I would want my start-up to be as lean as possible, so I would only load the bare minimum packages I need.
start_plumber <- function() {
library(tidyverse)
library(tidymodels)
library(vetiver)
library(pins)
library(plumber)
v <- vetiver_pin_read(board_local(), "pokemon_rf")
pr() %>% vetiver_pr_predict(v) %>% pr_run(port = 8088)
}Look at how straightforward it is to host a model with vetiver and plumber! I can actually take my model and start hosting a prediction endpoint in a single line of code. That’s wonderful.
Now I need to serve the API. I’m going to use the callr package to create an R process in the background that will call this function and start waiting for invocations. This R process will exist until it either errors or I kill it.
plumber_process <- callr::r_bg(start_plumber)From within R I can use vetiver_endpoint to create an object that can be used with the predict generic, as if the endpoint were a model itself.
endpoint <- vetiver_endpoint("http://127.0.0.1:8088/predict")
pokemon_test %>%
head(5) %>%
predict(endpoint, .)
#> # A tibble: 5 × 1
#> .pred_class
#> <chr>
#> 1 Bug
#> 2 Bug
#> 3 Psychic
#> 4 Bug
#> 5 Bug Of course, I can also query this endpoint outside of R. Here I’m going to use the jsonlite package to convert the first 5 rows of pokemon_test into a JSON, and the httr package to POST that JSON to the prediction endpoint. I’ll then convert the JSON back into a tibble (data frame).
response <- httr::POST(
"http://127.0.0.1:8088/predict",
body = pokemon_test %>% head(5) %>% jsonlite::toJSON()
)
httr::content(response, as = "text", encoding = "UTF-8") %>%
jsonlite::fromJSON() %>%
as_tibble()
#> # A tibble: 5 × 1
#> .pred_class
#> <chr>
#> 1 Bug
#> 2 Bug
#> 3 Psychic
#> 4 Bug
#> 5 Bug I could have submitted that POST request from anywhere on my local machine. I could query my API from a Python kernel running in Jupyter, or from the terminal.
As a clean-up step, I need to kill that Plumber process:
plumber_process$kill()I’ve only scratched the surface here but so far it looks like vetiver is a wonderful package. It accomplishes so much with an extraordinarily simple API. Thank you to Julia and the tidymodels team for their contribution to the R MLOps ecosystem!
The image at the top of this page is by George Becker and is used under the terms of the Pexels License.
devtools::session_info()
#> ─ Session info ───────────────────────────────────────────────────────────────
#> setting value
#> version R version 4.1.0 (2021-05-18)
#> os macOS Big Sur 11.3
#> system aarch64, darwin20
#> ui X11
#> language (EN)
#> collate en_AU.UTF-8
#> ctype en_AU.UTF-8
#> tz Australia/Melbourne
#> date 2022-01-25
#> pandoc 2.11.4 @ /Applications/RStudio.app/Contents/MacOS/pandoc/ (via rmarkdown)
#>
#> ─ Packages ───────────────────────────────────────────────────────────────────
#> package * version date (UTC) lib source
#> assertthat 0.2.1 2019-03-21 [1] CRAN (R 4.1.0)
#> backports 1.4.1 2021-12-13 [1] CRAN (R 4.1.1)
#> bit 4.0.4 2020-08-04 [1] CRAN (R 4.1.0)
#> bit64 4.0.5 2020-08-30 [1] CRAN (R 4.1.0)
#> brio 1.1.3 2021-11-30 [1] CRAN (R 4.1.1)
#> broom * 0.7.11 2022-01-03 [1] CRAN (R 4.1.1)
#> butcher 0.1.5 2021-06-28 [1] CRAN (R 4.1.0)
#> cachem 1.0.6 2021-08-19 [1] CRAN (R 4.1.1)
#> callr 3.7.0 2021-04-20 [1] CRAN (R 4.1.0)
#> cellranger 1.1.0 2016-07-27 [1] CRAN (R 4.1.0)
#> class 7.3-20 2022-01-13 [1] CRAN (R 4.1.1)
#> cli 3.1.1 2022-01-20 [1] CRAN (R 4.1.0)
#> codetools 0.2-18 2020-11-04 [1] CRAN (R 4.1.0)
#> colorspace 2.0-2 2021-06-24 [1] CRAN (R 4.1.1)
#> crayon 1.4.2 2021-10-29 [1] CRAN (R 4.1.1)
#> DBI 1.1.2 2021-12-20 [1] CRAN (R 4.1.1)
#> dbplyr 2.1.1 2021-04-06 [1] CRAN (R 4.1.0)
#> desc 1.4.0 2021-09-28 [1] CRAN (R 4.1.1)
#> devtools 2.4.3 2021-11-30 [1] CRAN (R 4.1.1)
#> dials * 0.0.10 2021-09-10 [1] CRAN (R 4.1.1)
#> DiceDesign 1.9 2021-02-13 [1] CRAN (R 4.1.0)
#> digest 0.6.29 2021-12-01 [1] CRAN (R 4.1.1)
#> downlit 0.4.0 2021-10-29 [1] CRAN (R 4.1.1)
#> dplyr * 1.0.7 2021-06-18 [1] CRAN (R 4.1.0)
#> ellipsis 0.3.2 2021-04-29 [1] CRAN (R 4.1.0)
#> evaluate 0.14 2019-05-28 [1] CRAN (R 4.1.0)
#> fansi 1.0.2 2022-01-14 [1] CRAN (R 4.1.1)
#> farver 2.1.0 2021-02-28 [1] CRAN (R 4.1.0)
#> fastmap 1.1.0 2021-01-25 [1] CRAN (R 4.1.0)
#> forcats * 0.5.1 2021-01-27 [1] CRAN (R 4.1.0)
#> foreach 1.5.1 2020-10-15 [1] CRAN (R 4.1.0)
#> fs 1.5.2 2021-12-08 [1] CRAN (R 4.1.1)
#> furrr 0.2.3 2021-06-25 [1] CRAN (R 4.1.0)
#> future 1.23.0 2021-10-31 [1] CRAN (R 4.1.1)
#> future.apply 1.8.1 2021-08-10 [1] CRAN (R 4.1.1)
#> generics 0.1.1 2021-10-25 [1] CRAN (R 4.1.1)
#> ggplot2 * 3.3.5 2021-06-25 [1] CRAN (R 4.1.1)
#> globals 0.14.0 2020-11-22 [1] CRAN (R 4.1.0)
#> glue 1.6.1 2022-01-22 [1] CRAN (R 4.1.0)
#> gower 0.2.2 2020-06-23 [1] CRAN (R 4.1.0)
#> GPfit 1.0-8 2019-02-08 [1] CRAN (R 4.1.0)
#> gtable 0.3.0 2019-03-25 [1] CRAN (R 4.1.0)
#> hardhat 0.1.6 2021-07-14 [1] CRAN (R 4.1.0)
#> haven 2.4.3 2021-08-04 [1] CRAN (R 4.1.1)
#> highr 0.9 2021-04-16 [1] CRAN (R 4.1.0)
#> hms 1.1.1 2021-09-26 [1] CRAN (R 4.1.1)
#> htmltools 0.5.2 2021-08-25 [1] CRAN (R 4.1.1)
#> httr 1.4.2 2020-07-20 [1] CRAN (R 4.1.0)
#> hugodown 0.0.0.9000 2021-09-18 [1] Github (r-lib/hugodown@168a361)
#> infer * 1.0.0 2021-08-13 [1] CRAN (R 4.1.1)
#> ipred 0.9-12 2021-09-15 [1] CRAN (R 4.1.1)
#> iterators 1.0.13 2020-10-15 [1] CRAN (R 4.1.0)
#> janitor 2.1.0 2021-01-05 [1] CRAN (R 4.1.0)
#> jsonlite 1.7.3 2022-01-17 [1] CRAN (R 4.1.0)
#> knitr 1.37 2021-12-16 [1] CRAN (R 4.1.1)
#> labeling 0.4.2 2020-10-20 [1] CRAN (R 4.1.0)
#> later 1.3.0 2021-08-18 [1] CRAN (R 4.1.1)
#> lattice 0.20-45 2021-09-22 [1] CRAN (R 4.1.1)
#> lava 1.6.10 2021-09-02 [1] CRAN (R 4.1.1)
#> lhs 1.1.3 2021-09-08 [1] CRAN (R 4.1.1)
#> lifecycle 1.0.1 2021-09-24 [1] CRAN (R 4.1.1)
#> listenv 0.8.0 2019-12-05 [1] CRAN (R 4.1.0)
#> lubridate 1.8.0 2021-10-07 [1] CRAN (R 4.1.1)
#> magrittr 2.0.1 2020-11-17 [1] CRAN (R 4.1.0)
#> MASS 7.3-55 2022-01-13 [1] CRAN (R 4.1.1)
#> Matrix 1.4-0 2021-12-08 [1] CRAN (R 4.1.1)
#> memoise 2.0.1 2021-11-26 [1] CRAN (R 4.1.1)
#> modeldata * 0.1.1 2021-07-14 [1] CRAN (R 4.1.0)
#> modelr 0.1.8 2020-05-19 [1] CRAN (R 4.1.0)
#> munsell 0.5.0 2018-06-12 [1] CRAN (R 4.1.0)
#> nnet 7.3-17 2022-01-13 [1] CRAN (R 4.1.1)
#> parallelly 1.30.0 2021-12-17 [1] CRAN (R 4.1.1)
#> parsnip * 0.1.7.9000 2021-10-11 [1] Github (tidymodels/parsnip@d1451da)
#> pillar 1.6.4 2021-10-18 [1] CRAN (R 4.1.1)
#> pins * 1.0.1 2021-12-15 [1] CRAN (R 4.1.1)
#> pkgbuild 1.3.1 2021-12-20 [1] CRAN (R 4.1.1)
#> pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.1.0)
#> pkgload 1.2.4 2021-11-30 [1] CRAN (R 4.1.1)
#> plumber * 1.1.0 2021-03-24 [1] CRAN (R 4.1.0)
#> plyr 1.8.6 2020-03-03 [1] CRAN (R 4.1.0)
#> prettyunits 1.1.1 2020-01-24 [1] CRAN (R 4.1.0)
#> pROC 1.18.0 2021-09-03 [1] CRAN (R 4.1.1)
#> processx 3.5.2 2021-04-30 [1] CRAN (R 4.1.0)
#> prodlim 2019.11.13 2019-11-17 [1] CRAN (R 4.1.0)
#> promises 1.2.0.1 2021-02-11 [1] CRAN (R 4.1.0)
#> ps 1.6.0 2021-02-28 [1] CRAN (R 4.1.0)
#> purrr * 0.3.4 2020-04-17 [1] CRAN (R 4.1.0)
#> R6 2.5.1 2021-08-19 [1] CRAN (R 4.1.1)
#> ranger 0.13.1 2021-07-14 [1] CRAN (R 4.1.0)
#> rappdirs 0.3.3 2021-01-31 [1] CRAN (R 4.1.0)
#> Rcpp 1.0.8 2022-01-13 [1] CRAN (R 4.1.1)
#> readr * 2.1.1 2021-11-30 [1] CRAN (R 4.1.1)
#> readxl 1.3.1 2019-03-13 [1] CRAN (R 4.1.0)
#> recipes * 0.1.17 2021-09-27 [1] CRAN (R 4.1.1)
#> remotes 2.4.2 2021-11-30 [1] CRAN (R 4.1.1)
#> reprex 2.0.1 2021-08-05 [1] CRAN (R 4.1.1)
#> rlang 0.4.12 2021-10-18 [1] CRAN (R 4.1.1)
#> rmarkdown 2.11 2021-09-14 [1] CRAN (R 4.1.1)
#> rpart 4.1-15 2019-04-12 [1] CRAN (R 4.1.0)
#> rprojroot 2.0.2 2020-11-15 [1] CRAN (R 4.1.0)
#> rsample * 0.1.1 2021-11-08 [1] CRAN (R 4.1.1)
#> rstudioapi 0.13 2020-11-12 [1] CRAN (R 4.1.0)
#> rvest 1.0.2 2021-10-16 [1] CRAN (R 4.1.1)
#> scales * 1.1.1 2020-05-11 [1] CRAN (R 4.1.0)
#> sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.1.1)
#> snakecase 0.11.0 2019-05-25 [1] CRAN (R 4.1.0)
#> stringi 1.7.6 2021-11-29 [1] CRAN (R 4.1.1)
#> stringr * 1.4.0 2019-02-10 [1] CRAN (R 4.1.0)
#> survival 3.2-13 2021-08-24 [1] CRAN (R 4.1.1)
#> swagger 3.33.1 2020-10-02 [1] CRAN (R 4.1.0)
#> testthat 3.1.2 2022-01-20 [1] CRAN (R 4.1.0)
#> tibble * 3.1.6 2021-11-07 [1] CRAN (R 4.1.1)
#> tidymodels * 0.1.4 2021-10-01 [1] CRAN (R 4.1.1)
#> tidyr * 1.1.4 2021-09-27 [1] CRAN (R 4.1.1)
#> tidyselect 1.1.1 2021-04-30 [1] CRAN (R 4.1.0)
#> tidyverse * 1.3.1 2021-04-15 [1] CRAN (R 4.1.0)
#> timeDate 3043.102 2018-02-21 [1] CRAN (R 4.1.0)
#> tune * 0.1.6 2021-07-21 [1] CRAN (R 4.1.0)
#> tzdb 0.2.0 2021-10-27 [1] CRAN (R 4.1.1)
#> usethis 2.1.5 2021-12-09 [1] CRAN (R 4.1.1)
#> utf8 1.2.2 2021-07-24 [1] CRAN (R 4.1.0)
#> vctrs 0.3.8 2021-04-29 [1] CRAN (R 4.1.0)
#> vetiver * 0.1.1.9000 2022-01-24 [1] Github (tidymodels/vetiver@7876706)
#> vroom 1.5.7 2021-11-30 [1] CRAN (R 4.1.1)
#> webutils 1.1 2020-04-28 [1] CRAN (R 4.1.0)
#> withr 2.4.3 2021-11-30 [1] CRAN (R 4.1.1)
#> workflows * 0.2.4 2021-10-12 [1] CRAN (R 4.1.1)
#> workflowsets * 0.1.0 2021-07-22 [1] CRAN (R 4.1.1)
#> xfun 0.29 2021-12-14 [1] CRAN (R 4.1.1)
#> xml2 1.3.3 2021-11-30 [1] CRAN (R 4.1.1)
#> yaml 2.2.1 2020-02-01 [1] CRAN (R 4.1.0)
#> yardstick * 0.0.9 2021-11-22 [1] CRAN (R 4.1.1)
#>
#> [1] /Library/Frameworks/R.framework/Versions/4.1-arm64/Resources/library
#>
#> ──────────────────────────────────────────────────────────────────────────────