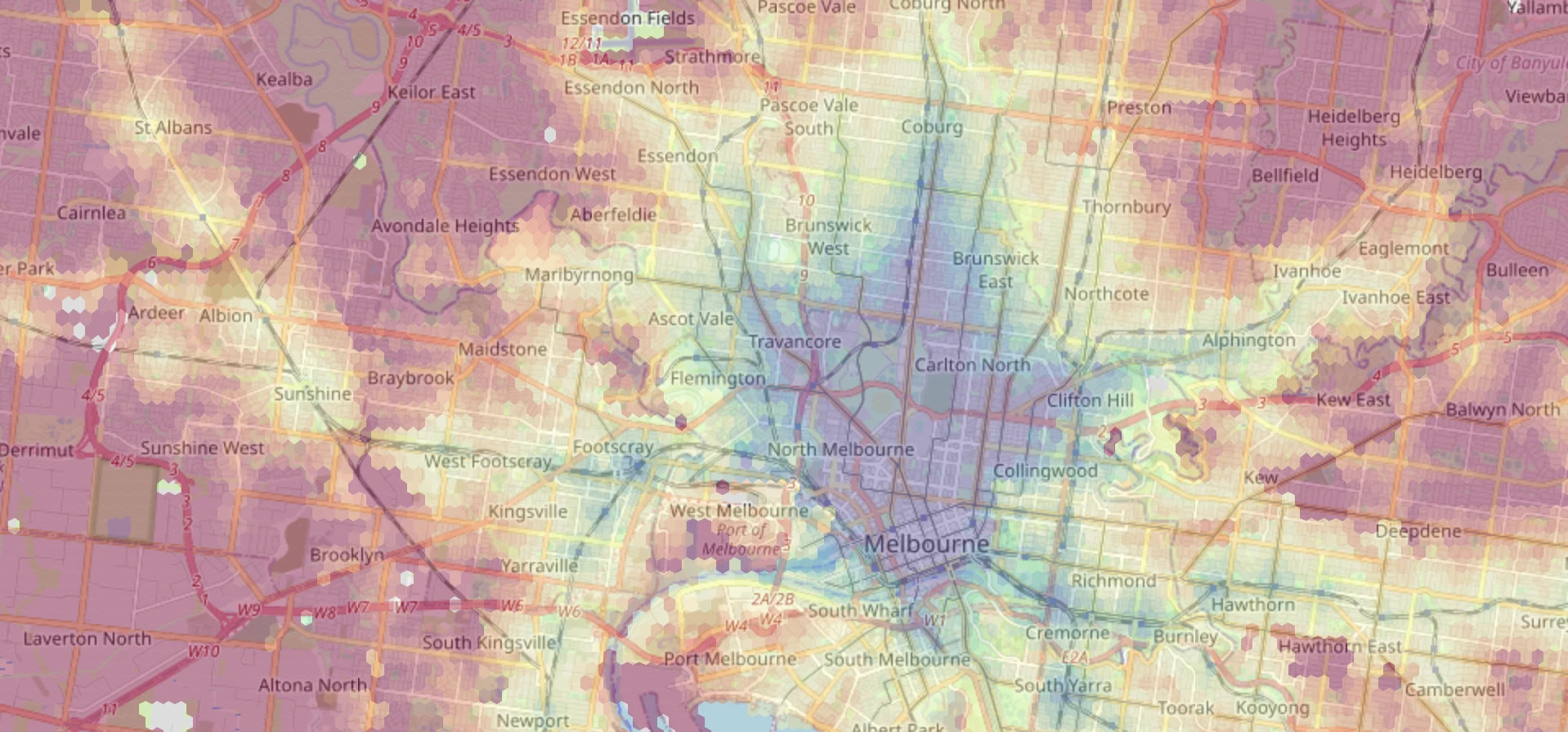
I’m house-hunting, and while I’d love to buy a 5-bedroom house with a pool 10 minutes walk from Flinders Street Station I probably can’t afford that. So I need to take a broader look at Melbourne.
One of the main constraints is commute time. I built a choropleth of commute times to the University of Melbourne and put it on top of a map of Melbourne.
The rough idea is to create a fine hexagonal grid across the city using the sf package, and then to pass the centre of each hexagon through the Google Maps Directions Matrix API with the help of the (Melbourne-made) googleway package. The results are plotted with leaflet and hosted for free on Netlify:
A warning if you want to recreate this for your own commute: the Distance Matrix API can end up costing a fair bit if you exceed the free tier. The above plot uses roughly 16K hexagons, although this can be adjusted by making the hexagons larger or querying fewer suburbs. Be sure to review the API pricing. I’m not responsible for any API charges you incur.
I am grateful to Belinda Maher, from whom I stole this idea.
Shape files and grids
The starting point a shape file for the Melbourne metropolitan area which I obtained from Plan Melbourne. It’s a simple polygon that outlines the region.
metro <- sf::read_sf("Administrative/Metropolitan region_region.shp")
plot(metro, main = "Melbourne")

The next step is to lay a grid of hexagons over the area. The centre of each hexagon will be used to determine commute time. More polygons means more granularity, but also a greater API cost.
sf::st_make_grid(metro, cellsize = 0.1, square = FALSE)[metro] %>% plot()
#> st_as_s2(): dropping Z and/or M coordinate

These hexagons are a little too large for a useful map. I’ll go with something much smaller. This covers the Melbourne metropolitan area with 170,000 hexagons:
metro_grid <- sf::st_make_grid(metro, cellsize = 0.0025, square = FALSE)[metro]
#> st_as_s2(): dropping Z and/or M coordinate
metro_grid
#> Geometry set for 170661 features
#> Geometry type: POLYGON
#> Dimension: XY
#> Bounding box: xmin: 144.4428 ymin: -38.50138 xmax: 146.1941 ymax: -37.38781
#> Geodetic CRS: GDA94
#> First 5 geometries:
#> POLYGON ((144.4441 -37.86485, 144.4428 -37.8641...
#> POLYGON ((144.4441 -37.86052, 144.4428 -37.8598...
#> POLYGON ((144.4453 -37.86268, 144.4441 -37.8619...
#> POLYGON ((144.4453 -37.85835, 144.4441 -37.8576...
#> POLYGON ((144.4453 -37.85402, 144.4441 -37.8533...
There are three ways to go from here:
- if your budget is unlimited, calculate the commute time for each suburb in
- a search method. Starting with the hexagon containing the commute destination, calculate commute time. Then calculate the commute time for the neighbouring hexagons of that hexagon. When a hexagon has a commute time over a certain limit (say, 1 hour), stop computing the commute times of its neighbours.
- a suburb-by-suburb method. Using a shape file of suburbs, calculate commute time for the hexagons in each suburb one at a time, manually.
I went with the suburb-by-suburb option here because I wanted to explore and get an idea of where I should be house-hunting. I used Melbourne localities provided by data.gov.au (the GDA94 version matches that of the Melbourne metro shape file). A quick function helps me get the hexagons in metro_grid that overlap any part of a suburb:
localities <- sf::read_sf("vic_localities/vic_localities.shp")
suburb_grid <- function(metro_grid, localities, suburb) {
assertthat::assert_that(suburb %in% localities$LOC_NAME)
suburb_shp <- localities %>% dplyr::filter(LOC_NAME == suburb)
grid_in_suburb <- metro_grid[suburb_shp]
assertthat::assert_that(length(grid_in_suburb) > 0)
grid_in_suburb
}The idea of taking a main set of hexagons (metro_grid) and then finding its intersection with a particular suburb is so that the hexagons in neighbouring suburbs tessellate.
Querying the Distance Matrix API
For each hexagon I take its centre and use it as the origin of a Google Maps Distance Matrix query. The destination is a fixed location that represents the input of my commute. Each query uses only public transport and asks for an arrival before 9am on a Monday to capture the typical workday commute. I’m using the following constants:
workplace <- c(144.9580, -37.8000)
monday_morning <- as.POSIXct("2023-01-30 09:00:00", tz = "Australia/Melbourne")I also need a helper function that converts a given set of hexagons into a matrix containing the coordinates of their centroids.
polygon_centroids <- function(polygons) {
polygons %>% sf::st_centroid() %>% sf::st_coordinates()
}I use the googleway package to query the Distance Matrix API. I have a “GOOGLE_MAPS_API_KEY” environment variable defined with my API key. Follow the instructions provided by Google, and be sure to enable the Distance Matrix API.
There’s an annoyance here in that Google expect latitude and longitude in a different order to the polygons I’m using. In my function I have a little hack for calculating rev_origin, which is the given origin but flipped. The origin is either a matrix of coordinates given by polygon_centroids or a vector representing a single origin point.
query_distance_matrix <- function(
origin,
destination = workplace,
arrival_time = monday_morning
) {
rev_origin <- if (is.matrix(origin) && nrow(origin) == 1) {
c(origin[1,2], origin[1,1])
} else if (is.matrix(origin)) {
as.data.frame(origin[, c(2, 1)])
} else {
rev(origin)
}
response <- googleway::google_distance(
origins = rev_origin,
destinations = rev(destination),
mode = "transit",
arrival_time = arrival_time,
units = "metric",
key = Sys.getenv("GOOGLE_MAPS_API_KEY")
)
if (response$status != "OK") {
stop(response$error_message)
}
response
}I also need some helper functions for extracting useful information from the raw response. These provide NA values when Google cannot find a route, which is likely to happen for hexagons that fall on areas like airport runways.
dm_origin_address <- function(response) response$origin_addresses
dm_matrix_response <- function(response) response$rows$elements
dm_distance <- function(response) {
response %>% dm_matrix_response() %>% purrr::map_int(
function(x) ifelse(x$status == "OK", x$distance$value, NA_integer_)
)
}
dm_time <- function(response) {
response %>% dm_matrix_response() %>% purrr::map_int(
function(x) ifelse(x$status == "OK", x$duration$value, NA_integer_)
)
}Gathering commute data
A single query to the Distance Matrix API can contain at most 25 origins, so this function must batch the requests. Each batch of 25 (or fewer) is queried against the API. The results are turned into a data frame alongside the original hexagons, the coordinates of their centres, and the data from the helper functions I’ve defined.
commute_facts <- function(polygons, destination = workplace) {
batch_size <- 25
n_polys <- polygons %>% length()
batches <- ceiling(n_polys / batch_size)
query_batch_number <- function(batch_number) {
batch_start <- batch_size * (batch_number - 1) + 1
batch_end <- min(batch_start + batch_size - 1, n_polys)
polygons_in_batch <- polygons[batch_start:batch_end]
coords_in_batch <- polygons_in_batch %>% polygon_centroids()
response <- query_distance_matrix(coords_in_batch, destination = destination)
dplyr::as_tibble(polygons_in_batch) %>%
cbind(coords_in_batch) %>%
dplyr::mutate(
origin = dm_origin_address(response),
commute_distance_m = dm_distance(response),
commute_time_s = dm_time(response),
commute_time = paste(round(commute_time_s / 60, 1), "minutes")
) %>%
dplyr::as_tibble()
}
purrr::map_dfr(seq(batches), query_batch_number) %>% dplyr::distinct()
}And here is the function in action for Brunswick:
grid_in_brunswick <- suburb_grid(metro_grid, localities, "Brunswick")
brunswick_commute_facts <- commute_facts(grid_in_brunswick)
brunswick_commute_facts
#> # A tibble: 121 × 7
#> geometry X Y origin commu…¹ commu…² commu…³
#> <POLYGON [°]> <dbl> <dbl> <chr> <int> <int> <chr>
#> 1 ((144.9478 -37.77175, 144.9466 -3… 145. -37.8 5 Fod… 4629 1459 24.3 m…
#> 2 ((144.9491 -37.77825, 144.9478 -3… 145. -37.8 Park … 3651 1110 18.5 m…
#> 3 ((144.9491 -37.77392, 144.9478 -3… 145. -37.8 14/19… 4221 1247 20.8 m…
#> 4 ((144.9491 -37.76959, 144.9478 -3… 145. -37.8 30 Pe… 4733 1518 25.3 m…
#> 5 ((144.9491 -37.76526, 144.9478 -3… 145. -37.8 95A P… 5557 1856 30.9 m…
#> 6 ((144.9491 -37.76093, 144.9478 -3… 145. -37.8 28 Ha… 6528 2003 33.4 m…
#> 7 ((144.9503 -37.77608, 144.9491 -3… 145. -37.8 26 He… 4007 1304 21.7 m…
#> 8 ((144.9503 -37.77175, 144.9491 -3… 145. -37.8 Grant… 4501 1326 22.1 m…
#> 9 ((144.9503 -37.76742, 144.9491 -3… 145. -37.8 460 V… 5394 1745 29.1 m…
#> 10 ((144.9503 -37.76309, 144.9491 -3… 145. -37.8 118 P… 5917 2124 35.4 m…
#> # … with 111 more rows, and abbreviated variable names ¹commute_distance_m,
#> # ²commute_time_s, ³commute_time
#> # ℹ Use `print(n = ...)` to see more rows
Avoiding repetition
If I try to calculate commute times for two adjacent suburbs, I’m going to have some overlap at the boundaries. API calls are expensive so it’s worth making sure I don’t query the same hexagon twice. The below function takes an existing data frame of commutes (like brunswick_commute_facts above) and adds commute facts from another suburb, being sure not to query data for any polygon I already know about.
I’m not proud of my method for detecting overlaps here. I resort to several lines of dplyr but it feels like there must be an easier way,
expand_commute_facts <- function(polygons, existing = NULL, destination = workplace) {
if (is.null(existing)) {
return(commute_facts(polygons, destination = destination))
}
polygon_df <- dplyr::as_tibble(polygon_centroids(polygons))
existing_df <- existing[c("X", "Y")] %>% dplyr::mutate(exists = TRUE)
existing_index <- polygon_df %>%
dplyr::left_join(existing_df, by = c("X", "Y")) %>%
dplyr::mutate(exists = ifelse(is.na(exists), FALSE, exists)) %>%
dplyr::pull(exists)
new_polygons <- polygons[!existing_index]
rbind(
existing,
commute_facts(new_polygons, destination = destination)
)
}I would then be able to add new commute facts like so:
fitzroy_and_brunswick_commute_facts <- expand_commute_facts(
suburb_grid(metro_grid, localities, "Fitzroy"),
existing = brunswick_commute_facts
)
fitzroy_and_brunswick_commute_facts
#> # A tibble: 162 × 7
#> geometry X Y origin commu…¹ commu…² commu…³
#> <POLYGON [°]> <dbl> <dbl> <chr> <int> <int> <chr>
#> 1 ((144.9478 -37.77175, 144.9466 -3… 145. -37.8 5 Fod… 4629 1459 24.3 m…
#> 2 ((144.9491 -37.77825, 144.9478 -3… 145. -37.8 Park … 3651 1110 18.5 m…
#> 3 ((144.9491 -37.77392, 144.9478 -3… 145. -37.8 14/19… 4221 1247 20.8 m…
#> 4 ((144.9491 -37.76959, 144.9478 -3… 145. -37.8 30 Pe… 4733 1518 25.3 m…
#> 5 ((144.9491 -37.76526, 144.9478 -3… 145. -37.8 95A P… 5557 1856 30.9 m…
#> 6 ((144.9491 -37.76093, 144.9478 -3… 145. -37.8 28 Ha… 6528 2003 33.4 m…
#> 7 ((144.9503 -37.77608, 144.9491 -3… 145. -37.8 26 He… 4007 1304 21.7 m…
#> 8 ((144.9503 -37.77175, 144.9491 -3… 145. -37.8 Grant… 4501 1326 22.1 m…
#> 9 ((144.9503 -37.76742, 144.9491 -3… 145. -37.8 460 V… 5394 1745 29.1 m…
#> 10 ((144.9503 -37.76309, 144.9491 -3… 145. -37.8 118 P… 5917 2124 35.4 m…
#> # … with 152 more rows, and abbreviated variable names ¹commute_distance_m,
#> # ²commute_time_s, ³commute_time
#> # ℹ Use `print(n = ...)` to see more rows
Map colours
Before I get to visualising the hexagons I want to define the colour legend. Everyone has different tolerances for commuting, but in my case I decided to set everything above 1 hour as the same colour as that used for 1 hour. I also set everything below 20 minutes as the same colour as that used for 20 minutes. This means that — for the purpose of the colour scale — I need to “clamp” my commute times to between 20 and 60 minutes. That is, values below 20 minutes will be raised to 20 and values above 60 minutes will be lowered to 60. These limits will be passed to my plotting function as min_value and max_value arguments.
# I wish this function was in base R
clamp_values <- function(values, min_value = NULL, max_value = NULL) {
if (is.null(min_value)) min_value <- min(values, na.rm = TRUE)
if (is.null(max_value)) max_value <- max(values, na.rm = TRUE)
clamped_values <- values
clamped_values[values > max_value] <- max_value
clamped_values[values < min_value] <- min_value
clamped_values
}I can then define my colours using leaflet’s colour palette functions. I have the option of reversing the palette, which I default to TRUE because I have the “spectral” palette in mind. Without reversing, red would represent lower values and blue would represent higher values, which defies convention.
clamped_palette_function <- function(palette, values, min_value = NULL, max_value = NULL, reverse_palette = TRUE) {
clamped_values <- clamp_values(values, min_value, max_value)
leaflet::colorNumeric(
palette,
reverse = reverse_palette,
domain = min(clamped_values):max(clamped_values)
)
}Map title
Leaflet doesn’t support titles out of the box (at least not through the R package, as far as I know). I adapted this solution from StackOverflow. It requires the creation of a CSS class for the title which can then be added to the Leaflet plot.
leaflet_title_class <- htmltools::tags$style(htmltools::HTML("
.leaflet-control.map-title {
transform: translate(-50%,20%);
position: fixed !important;
left: 38%;
max-width: 50%;
text-align: center;
padding-left: 5px;
padding-right: 5px;
background: rgba(255,255,255,0.75);
font-weight: bold;
font-size: 1.0em;
}
"))
leaflet_title <- htmltools::tags$div(
leaflet_title_class,
htmltools::HTML("Public transport commute time to University of Melbourne<br>by David Neuzerling")
)Leaflet plot
With all of the pieces in place I can now define my plot_commutes function. The layers are built up:
- I first create the empty plot and add the title
- I add the actual map of Melbourne from OpenStreetMap
- I centre the map on the commute destination and set the zoom level
- I add the hexagon plot with the colour scale I defined earlier. By setting
weight = 0I can remove the borders around each hexagon so that the colours blend a little. The labels will show the actual commute time when the user hovers over a hexagon (if on desktop) or taps on a hexagon (if on mobile). - I add the legend, formatting the commute time (which is in seconds) as minutes
plot_commutes <- function(
polygons,
colour_by,
destination = workplace,
min_value = 20 * 60,
max_value = 60 * 60
) {
non_na_polygons <- dplyr::filter(polygons, !is.na(commute_time_s))
leaflet::leaflet() %>%
leaflet::addControl(leaflet_title, position = "topleft", className = "map-title") %>%
leaflet::addProviderTiles("OpenStreetMap") %>%
leaflet::setView(lng = destination[1], lat = destination[2], zoom = 11) %>%
leaflet::addPolygons(
data = sf::st_transform(non_na_polygons$geometry, "+proj=longlat +datum=WGS84"),
fillColor = clamped_palette(
"Spectral",
non_na_polygons$commute_time_s,
min_value = min_value,
max_value = max_value
),
fillOpacity = 0.4,
weight = 0,
label = non_na_polygons$commute_time
) %>%
leaflet::addLegend(
title = "commute time",
pal = clamped_palette_function(
"Spectral",
non_na_polygons$commute_time_s,
min_value = min_value,
max_value = max_value
),
values = clamp_values(non_na_polygons$commute_time_s, min_value, max_value),
labFormat = leaflet::labelFormat(
suffix = " min",
transform = function(x) round(x / 60)
)
)
}Saving the widget
I use the htmlwidgets package to export the leaflet plot as a HTML site. Before doing so I need to define the “viewport” that allows mobile devices to properly display the map. Without this they would attempt to render the plot as if viewing on a desktop computer which would make the text far too small to read.
viewport <- htmltools::tags$meta(
name = "viewport",
content = "width=device-width, initial-scale=1.0"
)
save_commute_plot <- function(commute_plot, file_path) {
commute_plot %>%
htmlwidgets::prependContent(viewport) %>%
htmlwidgets::saveWidget(file_path)
}The resulting directory can be uploaded to any web server or static site hosting service, such as Netlify.
devtools::session_info()
#> ─ Session info ───────────────────────────────────────────────────────────────
#> setting value
#> version R version 4.2.1 (2022-06-23)
#> os macOS Big Sur 11.3
#> system aarch64, darwin20
#> ui X11
#> language (EN)
#> collate en_AU.UTF-8
#> ctype en_AU.UTF-8
#> tz Australia/Melbourne
#> date 2023-02-12
#> pandoc 2.18 @ /Applications/RStudio.app/Contents/MacOS/quarto/bin/tools/ (via rmarkdown)
#>
#> ─ Packages ───────────────────────────────────────────────────────────────────
#> package * version date (UTC) lib source
#> assertthat 0.2.1 2019-03-21 [1] CRAN (R 4.2.0)
#> cachem 1.0.6 2021-08-19 [1] CRAN (R 4.2.0)
#> callr 3.7.1 2022-07-13 [1] CRAN (R 4.2.0)
#> class 7.3-20 2022-01-16 [1] CRAN (R 4.2.1)
#> classInt 0.4-7 2022-06-10 [1] CRAN (R 4.2.0)
#> cli 3.6.0 2023-01-09 [1] CRAN (R 4.2.0)
#> crayon 1.5.2 2022-09-29 [1] CRAN (R 4.2.0)
#> crosstalk 1.2.0 2021-11-04 [1] CRAN (R 4.2.0)
#> curl 5.0.0 2023-01-12 [1] CRAN (R 4.2.0)
#> DBI 1.1.3 2022-06-18 [1] CRAN (R 4.2.0)
#> devtools 2.4.4 2022-07-20 [1] CRAN (R 4.2.0)
#> digest 0.6.31 2022-12-11 [1] CRAN (R 4.2.0)
#> downlit 0.4.2 2022-07-05 [1] CRAN (R 4.2.0)
#> dplyr * 1.0.9 2022-04-28 [1] CRAN (R 4.2.0)
#> e1071 1.7-11 2022-06-07 [1] CRAN (R 4.2.0)
#> ellipsis 0.3.2 2021-04-29 [1] CRAN (R 4.2.0)
#> evaluate 0.20 2023-01-17 [1] CRAN (R 4.2.0)
#> fansi 1.0.4 2023-01-22 [1] CRAN (R 4.2.0)
#> fastmap 1.1.0 2021-01-25 [1] CRAN (R 4.2.0)
#> fs 1.6.0 2023-01-23 [1] CRAN (R 4.2.0)
#> generics 0.1.3 2022-07-05 [1] CRAN (R 4.2.0)
#> glue 1.6.2 2022-02-24 [1] CRAN (R 4.2.0)
#> googleway 2.7.6 2022-01-24 [1] CRAN (R 4.2.0)
#> highr 0.10 2022-12-22 [1] CRAN (R 4.2.0)
#> htmltools 0.5.4 2022-12-07 [1] CRAN (R 4.2.0)
#> htmlwidgets 1.5.4 2021-09-08 [1] CRAN (R 4.2.0)
#> httpuv 1.6.5 2022-01-05 [1] CRAN (R 4.2.0)
#> hugodown 0.0.0.9000 2023-01-26 [1] Github (r-lib/hugodown@f6f23dd)
#> jsonlite 1.8.4 2022-12-06 [1] CRAN (R 4.2.0)
#> KernSmooth 2.23-20 2021-05-03 [1] CRAN (R 4.2.1)
#> knitr 1.42 2023-01-25 [1] CRAN (R 4.2.0)
#> later 1.3.0 2021-08-18 [1] CRAN (R 4.2.0)
#> leaflet 2.1.1 2022-03-23 [1] CRAN (R 4.2.0)
#> lifecycle 1.0.3 2022-10-07 [1] CRAN (R 4.2.0)
#> magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.2.0)
#> memoise 2.0.1 2021-11-26 [1] CRAN (R 4.2.0)
#> mime 0.12 2021-09-28 [1] CRAN (R 4.2.0)
#> miniUI 0.1.1.1 2018-05-18 [1] CRAN (R 4.2.0)
#> pillar 1.8.0 2022-07-18 [1] CRAN (R 4.2.1)
#> pkgbuild 1.3.1 2021-12-20 [1] CRAN (R 4.2.0)
#> pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.2.0)
#> pkgload 1.3.0 2022-06-27 [1] CRAN (R 4.2.0)
#> prettyunits 1.1.1 2020-01-24 [1] CRAN (R 4.2.0)
#> processx 3.8.0 2022-10-26 [1] CRAN (R 4.2.0)
#> profvis 0.3.7 2020-11-02 [1] CRAN (R 4.2.0)
#> promises 1.2.0.1 2021-02-11 [1] CRAN (R 4.2.0)
#> proxy 0.4-27 2022-06-09 [1] CRAN (R 4.2.0)
#> ps 1.7.2 2022-10-26 [1] CRAN (R 4.2.0)
#> purrr 1.0.1 2023-01-10 [1] CRAN (R 4.2.0)
#> R6 2.5.1 2021-08-19 [1] CRAN (R 4.2.0)
#> Rcpp 1.0.10 2023-01-22 [1] CRAN (R 4.2.0)
#> remotes 2.4.2 2021-11-30 [1] CRAN (R 4.2.0)
#> rlang 1.0.6 2022-09-24 [1] CRAN (R 4.2.0)
#> rmarkdown 2.20 2023-01-19 [1] CRAN (R 4.2.0)
#> rstudioapi 0.14 2022-08-22 [1] CRAN (R 4.2.0)
#> s2 1.1.0 2022-07-18 [1] CRAN (R 4.2.0)
#> sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.2.0)
#> sf 1.0-9 2022-11-08 [1] CRAN (R 4.2.0)
#> shiny 1.7.2 2022-07-19 [1] CRAN (R 4.2.0)
#> stringi 1.7.12 2023-01-11 [1] CRAN (R 4.2.0)
#> stringr 1.5.0 2022-12-02 [1] CRAN (R 4.2.0)
#> tibble 3.1.8 2022-07-22 [1] CRAN (R 4.2.0)
#> tidyselect 1.1.2 2022-02-21 [1] CRAN (R 4.2.0)
#> units 0.8-0 2022-02-05 [1] CRAN (R 4.2.0)
#> urlchecker 1.0.1 2021-11-30 [1] CRAN (R 4.2.0)
#> usethis 2.1.6 2022-05-25 [1] CRAN (R 4.2.0)
#> utf8 1.2.2 2021-07-24 [1] CRAN (R 4.2.0)
#> vctrs 0.5.2 2023-01-23 [1] CRAN (R 4.2.0)
#> withr 2.5.0 2022-03-03 [1] CRAN (R 4.2.0)
#> wk 0.6.0 2022-01-03 [1] CRAN (R 4.2.0)
#> xfun 0.36 2022-12-21 [1] CRAN (R 4.2.0)
#> xtable 1.8-4 2019-04-21 [1] CRAN (R 4.2.0)
#> yaml 2.3.7 2023-01-23 [1] CRAN (R 4.2.0)
#>
#> [1] /Library/Frameworks/R.framework/Versions/4.2-arm64/Resources/library
#>
#> ──────────────────────────────────────────────────────────────────────────────