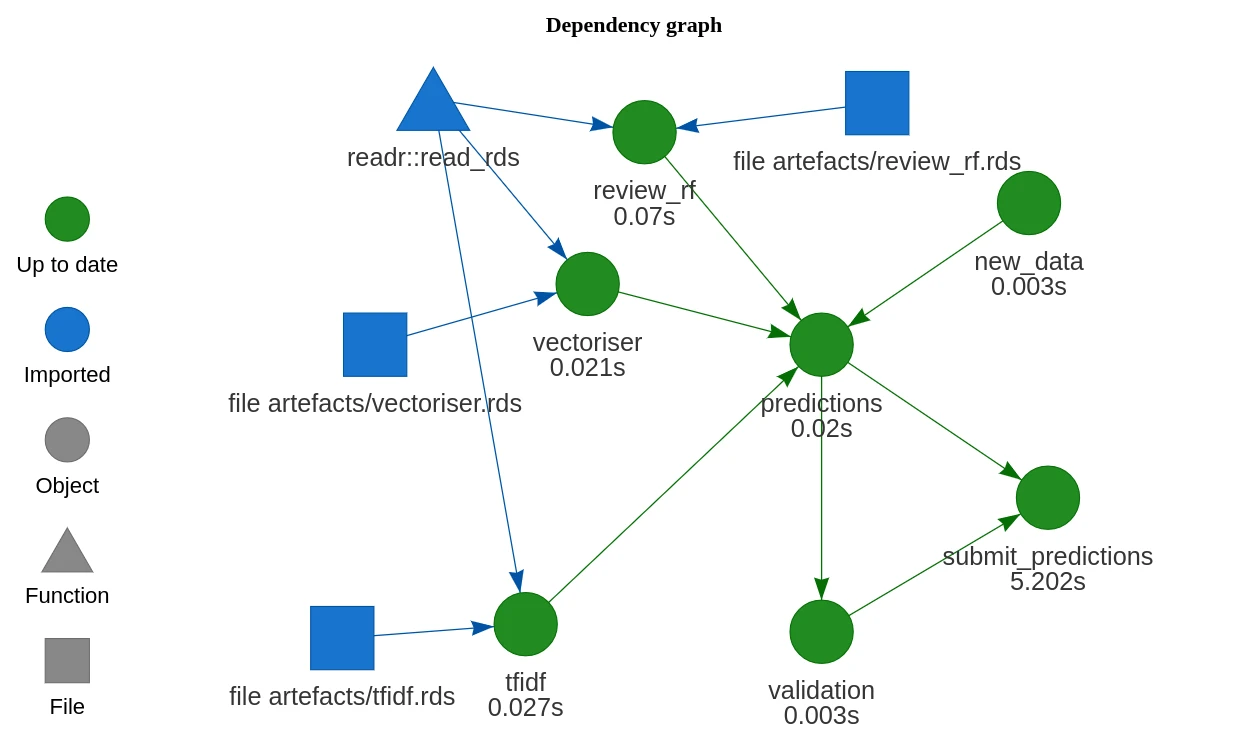
Drake is my new favourite R package.
Drake is a tool for orchestrating complicated workflows. You piece together a plan based on some high-level, abstract functions. These functions should be pure — they need to be defined by their inputs only, not relying on any predefined variables that aren’t in the function signature. Then, drake will take the steps in that plan and work out how to run it. Here’s how I’ve defined the plan above:
drake::drake_plan(
new_data = new_data_to_be_scored(),
tfidf = readr::read_rds(file_in("artefacts/tfidf.rds")),
vectoriser = readr::read_rds(file_in("artefacts/vectoriser.rds")),
review_rf = readr::read_rds(file_in("artefacts/review_rf.rds")),
predictions = sentiment(new_data$review,
random_forest = review_rf,
vectoriser = vectoriser,
tfidf = tfidf),
validation = validate_predictions(predictions),
submit_predictions = target(
submit_predictions(predictions),
trigger = trigger(condition = validation, mode = "blacklist")
)
)Drake is magic. I’m not going to go through the intricacies of this plan or how drake works, since the drake documentation is some of the best I’ve ever seen for an R package. But here are some reasons to use drake:
- It doesn’t matter what order you declare the steps, as drake is smart enough to determine the dependencies between them.
- If you change something in a step halfway through the plan, drake will work out what needs to be rerun and only rerun that. Drake frees you from having to work out what parts of your code you need to execute when you make a change.
- You’ll never need a directory of files with names like “01-setup.R”, “02-source-data.R”, etc. ever again.
- Drake can work out which steps of your plan can be parallelised, and makes it easier to do so.
- You’ll be encouraged to think about your project execution in terms of pure functions. R is idiomatically a functional language, and that’s the style that makes drake work.
I came across this powerful package when I was researching best practices for R. I wanted to see if I could fit drake into some sort of standardised approach to training and implementing a machine learning model.
Project workflows
When it comes to code, there are three major components to a machine learning project:
- Exploratory data analysis (EDA)
- Model training
- Model execution
These components are run independently of each other. EDA is a largely human task, and is usually only performed when the model is created or updated in some major way. The other two components need not operate together — if model retraining is expensive, or new training data is infrequently available, we might retrain a model on some monthly basis while scoring new data on a daily basis.
I pieced together a template that implements these three components using R-specific tools:
- EDA — R Markdown
- Model training — drake
- Model execution — drake
All three of these components might use similar functions. Typically we would place all of these functions in a directory (almost always called R/) and source them as needed. Here I want to try to combine these components into a custom R package.
R packages are the standard for complicated R projects. With packages, we gain access to the comprehensive R CMD CHECK, as well as testthat unit tests and roxygen2 documentation. I’m certainly not the first to combine drake with a package workflow, but I wanted to have a single repository that combines all elements of a machine learning project.
This template uses a simple random forest sentiment analysis model, based on labelled data available from the UCI machine learning repository. Drake takes care of the data caching for us. This means that we can, say, adjust the hyper-parameters of our model and rerun the training plan, and only the modelling step and onward will be rerun.
This template considers machine learning workflows intended to be executed in batch — for models that run as APIs, consider using plumber instead.
Training and execution
After cloning the repo, navigate to the directory in which the files are located. The easiest way to do this is to open the project in RStudio.
Model training and execution plans are generated by functions in the package. The package doesn’t actually need to be installed — we can use devtools::load_all() to simulate the installation. The model can be trained with:
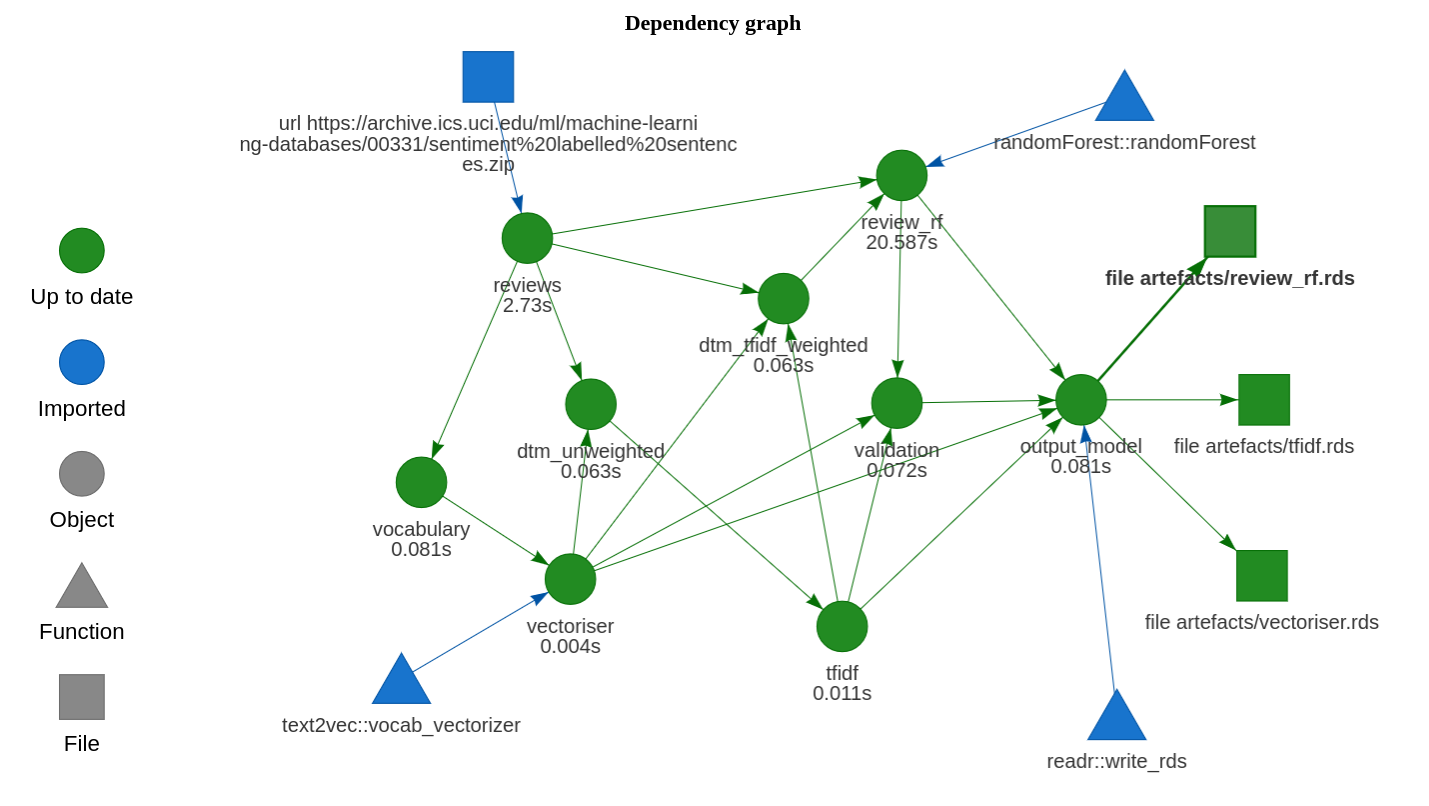
Plot the plan with drake::vis_drake_graph:
Model execution is run similarly:
Model artefacts — the random forest model, the vectoriser, and the tfidf weightings — are saved to and loaded from the artefacts directory. This is an arbitrary choice. We could just as easily use a different directory or remote storage.
I’ve simulated a production step with a new_data_to_be_scored function that returns a few reviews to be scored. Predictions are “submitted” through the submit_prediction() function. This function does nothing except sleep for 5 seconds. In practice we would submit model output wherever it needs to go — locally, a cloud service, etc. It’s hard to “productionise” a model when it’s just a toy.
The exploratory data analysis piece can be found in the inst/eda/ directory. It’s a standard R Markdown file, and can be compiled with knitr.
Model and prediction verification
Both training and execution plans include a verification step. These are functions that — using the assertthat package — ensure certain basic facts about the model and its predictions are true. If any of these assertions is false, an error is returned.
validate_model <- function(random_forest, vectoriser, tfidf = NULL) {
model_sentiment <- function(x) sentiment(x, random_forest, vectoriser, tfidf)
oob <- random_forest$err.rate[random_forest$ntree, "OOB"] # out of bag error
assertthat::assert_that(model_sentiment("love") == "good")
assertthat::assert_that(model_sentiment("bad") == "bad")
assertthat::assert_that(oob < 0.4)
TRUE
}The model artefacts and predictions cannot be exported without passing this verification step. Their relevant drake targets are conditioned on the validation function returning TRUE:
output_model = drake::target(
{
dir.create("artefacts", showWarnings = FALSE)
readr::write_rds(vectoriser, file_out("artefacts/vectoriser.rds"))
readr::write_rds(tfidf, file_out("artefacts/tfidf.rds"))
readr::write_rds(review_rf, file_out("artefacts/review_rf.rds"))
},
trigger = drake::trigger(condition = validation, mode = "blacklist")
)For example, suppose I changed the assertion above to demand that my model must have an out-of-bag error of less than 0.01% before it can be exported. My model isn’t very good, however, so that step will error. The execution steps are dependent on that validation, and so they won’t be run.
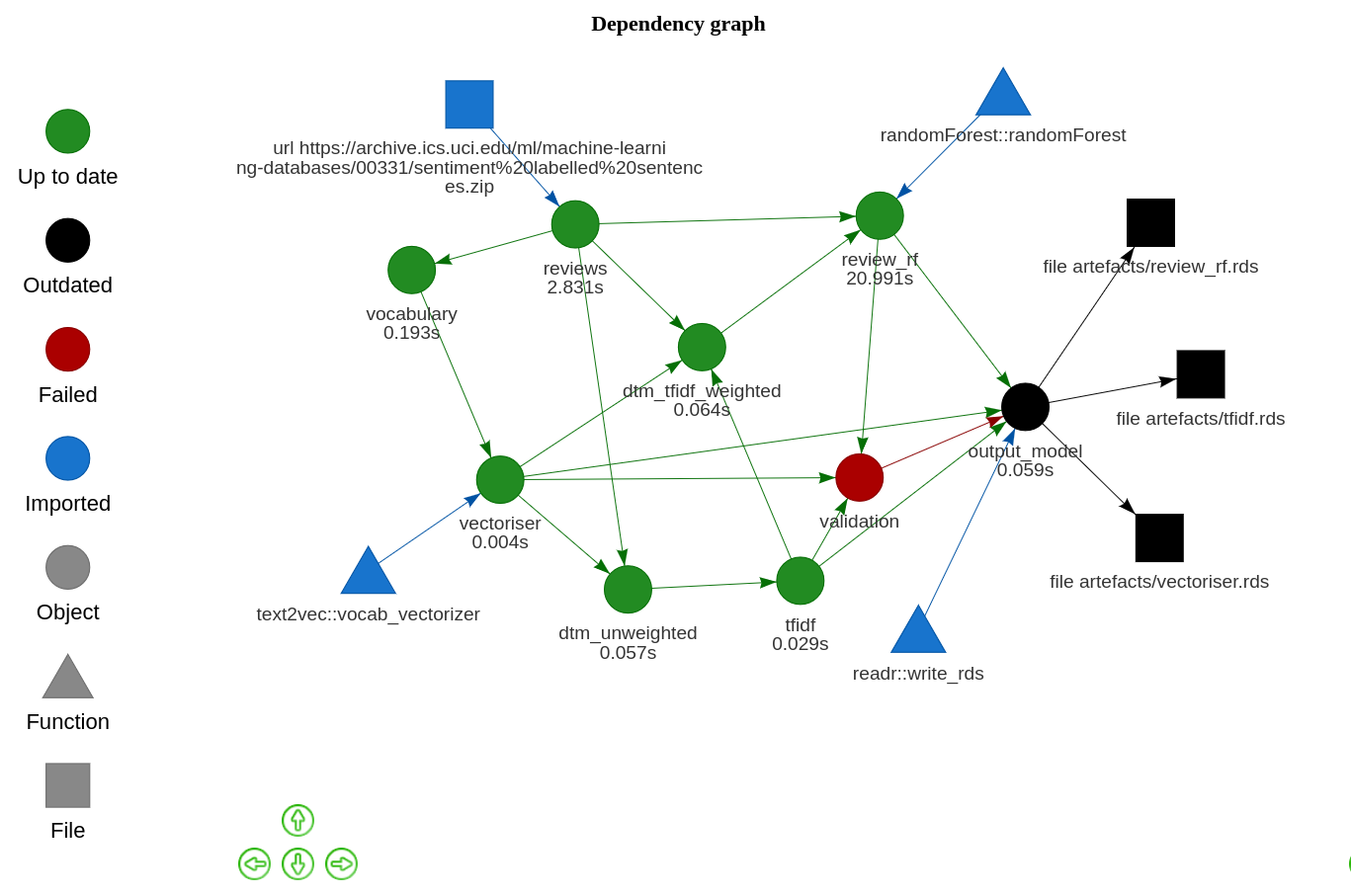
The assertions I’ve included here are very basic. However, I think these steps of the plans are important and extensible. We could assert that a model:
- produces sensible outputs, based on type or domain.
- has an accuracy above a given threshold, based on one or more metrics.
- does not produce outputs that are biased against a particular group.
We could also assert that predictions of new data:
- are sensible.
- do not contain sensitive data.
- are not biased against particular groups.
Not the best practice
If you’re interested, I’ve put the template up as a git repository, DrakeModelling.
This wasn’t my first attempt to template a machine learning workflow. Before I discovered drake I tried to structure a model as a package such that installing the package was the same as training the model. I did this by having a vignette for model training, which inserted artefacts into the package.
It’s a pretty fun way to train a model. Imagine installing a package and triggering a 12-hour model training process? But it’s not a very clean approach. Hadley said it was like “fixing the plane while flying it”, and he wasn’t wrong.
devtools::session_info()
#> ─ Session info ───────────────────────────────────────────────────────────────
#> setting value
#> version R version 4.0.0 (2020-04-24)
#> os Ubuntu 20.04 LTS
#> system x86_64, linux-gnu
#> ui X11
#> language en_AU:en
#> collate en_AU.UTF-8
#> ctype en_AU.UTF-8
#> tz Australia/Melbourne
#> date 2020-06-21
#>
#> ─ Packages ───────────────────────────────────────────────────────────────────
#> package * version date lib source
#> assertthat 0.2.1 2019-03-21 [1] CRAN (R 4.0.0)
#> backports 1.1.8 2020-06-17 [1] CRAN (R 4.0.0)
#> callr 3.4.3 2020-03-28 [1] CRAN (R 4.0.0)
#> cli 2.0.2 2020-02-28 [1] CRAN (R 4.0.0)
#> crayon 1.3.4 2017-09-16 [1] CRAN (R 4.0.0)
#> desc 1.2.0 2018-05-01 [1] CRAN (R 4.0.0)
#> devtools 2.3.0 2020-04-10 [1] CRAN (R 4.0.0)
#> digest 0.6.25 2020-02-23 [1] CRAN (R 4.0.0)
#> downlit 0.0.0.9000 2020-06-15 [1] Github (r-lib/downlit@9191e1f)
#> ellipsis 0.3.1 2020-05-15 [1] CRAN (R 4.0.0)
#> evaluate 0.14 2019-05-28 [1] CRAN (R 4.0.0)
#> fansi 0.4.1 2020-01-08 [1] CRAN (R 4.0.0)
#> fs 1.4.1 2020-04-04 [1] CRAN (R 4.0.0)
#> glue 1.4.1 2020-05-13 [1] CRAN (R 4.0.0)
#> htmltools 0.5.0 2020-06-16 [1] CRAN (R 4.0.0)
#> hugodown 0.0.0.9000 2020-06-20 [1] Github (r-lib/hugodown@f7df565)
#> knitr 1.28 2020-02-06 [1] CRAN (R 4.0.0)
#> magrittr 1.5 2014-11-22 [1] CRAN (R 4.0.0)
#> memoise 1.1.0.9000 2020-05-09 [1] Github (hadley/memoise@4aefd9f)
#> pkgbuild 1.0.7 2020-04-25 [1] CRAN (R 4.0.0)
#> pkgload 1.0.2 2018-10-29 [1] CRAN (R 4.0.0)
#> prettyunits 1.1.1 2020-01-24 [1] CRAN (R 4.0.0)
#> processx 3.4.2 2020-02-09 [1] CRAN (R 4.0.0)
#> ps 1.3.3 2020-05-08 [1] CRAN (R 4.0.0)
#> R6 2.4.1 2019-11-12 [1] CRAN (R 4.0.0)
#> remotes 2.1.1 2020-02-15 [1] CRAN (R 4.0.0)
#> rlang 0.4.6 2020-05-02 [1] CRAN (R 4.0.0)
#> rmarkdown 2.3.1 2020-06-20 [1] Github (rstudio/rmarkdown@b53a85a)
#> rprojroot 1.3-2 2018-01-03 [1] CRAN (R 4.0.0)
#> sessioninfo 1.1.1 2018-11-05 [1] CRAN (R 4.0.0)
#> stringi 1.4.6 2020-02-17 [1] CRAN (R 4.0.0)
#> stringr 1.4.0 2019-02-10 [1] CRAN (R 4.0.0)
#> testthat 2.3.2 2020-03-02 [1] CRAN (R 4.0.0)
#> usethis 1.6.1 2020-04-29 [1] CRAN (R 4.0.0)
#> withr 2.2.0 2020-04-20 [1] CRAN (R 4.0.0)
#> xfun 0.14 2020-05-20 [1] CRAN (R 4.0.0)
#> yaml 2.2.1 2020-02-01 [1] CRAN (R 4.0.0)
#>
#> [1] /home/mdneuzerling/R/x86_64-pc-linux-gnu-library/4.0
#> [2] /usr/local/lib/R/site-library
#> [3] /usr/lib/R/site-library
#> [4] /usr/lib/R/library