
My knowledge of wine covers three facts:
- I like red wine.
- I do not like white wine.
- I love wine data.
I came across a great collection of around 130,000 wine reviews, each a paragraph long, on Kaggle. This is juicy stuff, and I can’t wait to dig into it with some text analysis, or maybe build some sort of markov chain or neural network that generates new wine reviews.
But I wanted to start with something simple—a little bit of feature engineering. There’s around 700 different varieties (eg. merlot, riesling) in here, and I thought it would be easy to add on whether or not they were red, white or rosé.
It was not.
I won’t show you all the failed attempts; I’ll just focus on what worked in the end. This is the process:
- Scrape wine colour data from Wikipedia
- Join the colours with the wine varieties
- Fix errors and duplicates
- Improve the wine colour data, and repeat
- When all else fails, manually classify what remains.
Classifying wine into three simple categories is a tough ask, and I can hear the connoisseurs tutting at me. Some grapes can be red and white, and I’m told that there’s such a thing as “orange” wine (and no, it’s not made from oranges—I did ask). Dessert wines and sparkling wines can probably be classified as red or white, but really they’re off doing their own thing. I acknowledge how aggressive this classification is, but I’m going to charge ahead anyway.
Quick look at the data
knitr::opts_chunk$set(echo = TRUE, cache = TRUE)
set.seed(42275) # Chosen by fair dice roll. Guaranteed to be random.
library(tidyverse)
library(ggplot2)
library(rvest)
red_wine_colour <- "#59121C"
white_wine_colour <- "#EADB9F"
rose_wine_colour <- "#F5C0A2"
wine <- "wine_reviews.csv" %>%
read_csv %>%
mutate(variety = variety %>% tolower)
wine %>% str
#> tibble [129,971 × 14] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
#> $ X1 : num [1:129971] 0 1 2 3 4 5 6 7 8 9 ...
#> $ country : chr [1:129971] "Italy" "Portugal" "US" "US" ...
#> $ description : chr [1:129971] "Aromas include tropical fruit, broom, brimstone and dried herb. The palate isn't overly expressive, offering un"| __truncated__ "This is ripe and fruity, a wine that is smooth while still structured. Firm tannins are filled out with juicy r"| __truncated__ "Tart and snappy, the flavors of lime flesh and rind dominate. Some green pineapple pokes through, with crisp ac"| __truncated__ "Pineapple rind, lemon pith and orange blossom start off the aromas. The palate is a bit more opulent, with note"| __truncated__ ...
#> $ designation : chr [1:129971] "Vulkà Bianco" "Avidagos" NA "Reserve Late Harvest" ...
#> $ points : num [1:129971] 87 87 87 87 87 87 87 87 87 87 ...
#> $ price : num [1:129971] NA 15 14 13 65 15 16 24 12 27 ...
#> $ province : chr [1:129971] "Sicily & Sardinia" "Douro" "Oregon" "Michigan" ...
#> $ region_1 : chr [1:129971] "Etna" NA "Willamette Valley" "Lake Michigan Shore" ...
#> $ region_2 : chr [1:129971] NA NA "Willamette Valley" NA ...
#> $ taster_name : chr [1:129971] "Kerin O’Keefe" "Roger Voss" "Paul Gregutt" "Alexander Peartree" ...
#> $ taster_twitter_handle: chr [1:129971] "@kerinokeefe" "@vossroger" "@paulgwine " NA ...
#> $ title : chr [1:129971] "Nicosia 2013 Vulkà Bianco (Etna)" "Quinta dos Avidagos 2011 Avidagos Red (Douro)" "Rainstorm 2013 Pinot Gris (Willamette Valley)" "St. Julian 2013 Reserve Late Harvest Riesling (Lake Michigan Shore)" ...
#> $ variety : chr [1:129971] "white blend" "portuguese red" "pinot gris" "riesling" ...
#> $ winery : chr [1:129971] "Nicosia" "Quinta dos Avidagos" "Rainstorm" "St. Julian" ...I think this data will keep me entertained for a while. There’s a lot to dig into here, and those reviews are going to be interesting when I can pull them apart. For example, 7 wines are described as tasting of tennis balls, and these wines are rated about average. It makes me think that I’m not spending enough time in life appreciating the taste of tennis balls. Dogs understand this.
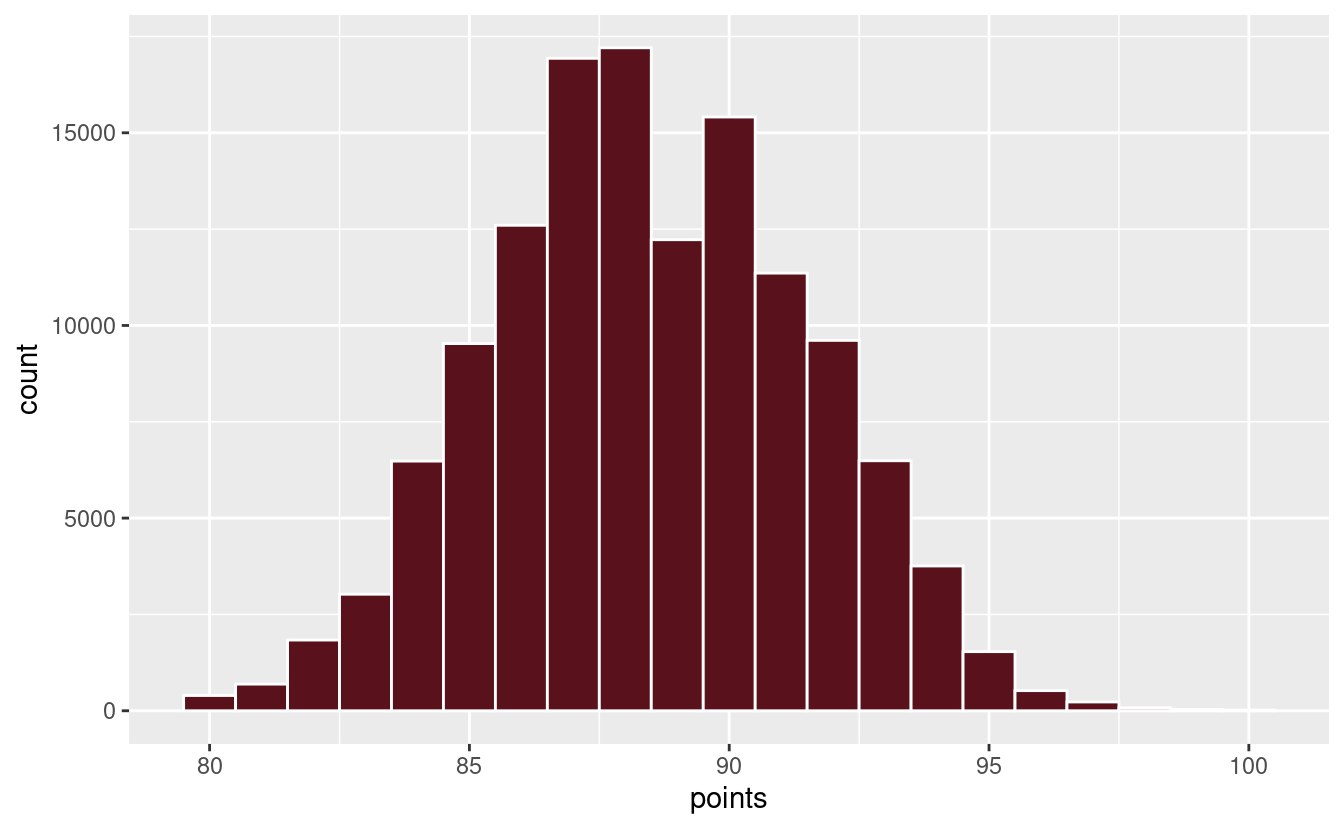
Speaking of points, it appears as though wines are ranked on a scale from 80 to 100. Although, looking at the plot below, you’d be forgiven for thinking that the scale is from 80 to 97. Only 0.01% of wines make it to a rating of 100.
wine %>% ggplot(aes(x = points)) +
geom_histogram(
bins = nrow(wine %>% distinct(points)),
colour = "white",
fill = red_wine_colour
)
The review below is for an 80-point wine, and it’s certainly one of my favourite descriptions:
wine %>%
filter(X1 == 11086) %>%
select(description) %>%
paste0('> ', .) %>% # print as quote
cat
Picture grandma standing over a pot of stewed prunes, which fill the dusty old house with their sickly aromas. Cooked, earthy and rustic, this wine has little going for it. Just barely acceptable.
One wine, indexed 86909, has a missing variety. Fortunately, we can recover the information from the review:
wine %>%
filter(X1 == 86909) %>%
select(description) %>%
paste0('> ', .) %>% # print as quote
cat
A chalky, dusty mouthfeel nicely balances this Petite Syrah’s bright, full blackberry and blueberry fruit. Wheat-flour and black-pepper notes add interest to the bouquet; the wine finishes with herb and an acorny nuttiness. A good first Chilean wine for those more comfortable with the Californian style. It’s got tannins to lose, but it’s very good.
wine <- wine %>% mutate(
variety = ifelse(X1 == 86909, "petite syrah", variety)
)Scraping Wikipedia
In order to classify the wines as red, white or rosé, we’re going to scrape wine data from the List of grape varieties Wikipedia page, using the rvest package. The first three tables of this page give red, white and rosé wines, in that order.
We’re going to use an older version of the article, dated 2018-06-29, for consistency. Wikipedia displays a notice that the user is reading an older version of the article. This counts as a table, and so the code below refers to tables 2, 3 and 4. If using the live version, replace these figures with 1, 2 and 3.
# Use an old revision of the article for consistency
wiki_tables <- "https://en.wikipedia.org/w/index.php?title=List_of_grape_varieties&oldid=847983339" %>%
read_html %>%
html_nodes("table")
red_wines <- wiki_tables[[1]] %>% html_table %>% cbind(colour = "red")
white_wines <- wiki_tables[[2]] %>% html_table %>% cbind(colour = "white")
rose_wines <- wiki_tables[[3]] %>% html_table %>% cbind(colour = "rosé")
all_wines <- rbind(red_wines, white_wines, rose_wines)
all_wines %>%
select(`Common Name(s)`, `All Synonyms`, colour) %>%
head(1)
#> Common Name(s) All Synonyms colour
#> 1 Abbuoto Aboto, Cecubo. redWe’re interested in three columns here: Common Name(s), All Synonyms and the colour column we defined from the table scraping. We will take the opportunity to rename the columns to match the tidyverse style.
Apart from synonyms, some wines can also have multiple common names, eg. “shiraz / syrah”. The synonyms seem to be very broad, and can include some unexpected results: pinot grigio (also known as pinot gris) is used to produce white wine, yet it appears as a synonym to canari noir, which is used to make red wine.
We’re going to preference the common names over the synonyms, so that in any conflict we use the colour as given by the common name. To do this, we’re going to unnest the common names and clean the results so that all entries are in lower-case, the results are distinct, and certain stray bits of punctuation are removed. We’re then going to do the same with the synonyms, but when we combine the results we will ignore all entries that are already provided by the common names.
The end result will be a single table with two columns: variety, and colour. The table may very well still contain duplicates, but certainly less than we would have had if we had treated common names and synonyms as equals.
all_wines_cleaned <- all_wines %>%
rename(
common_names = `Common Name(s)`,
synonyms = `All Synonyms`
) %>%
mutate_all(tolower) %>%
select(common_names, synonyms, colour)
common_names <- all_wines_cleaned %>%
unnest(common_names = strsplit(common_names, " / ")) %>% # split common names into separate rows
rename(variety = common_names) %>%
mutate(
variety = gsub("\\.", "", variety), # remove periods
variety = gsub("\\s*\\([^\\)]+\\)", "", variety), # remove brackets and anything within
variety = gsub("\\s*\\[[^\\)]+\\]", "", variety) # same for square brackets
) %>%
select(variety, colour)
#> Warning: unnest() has a new interface. See ?unnest for details.
#> Try `df %>% unnest(c(common_names))`, with `mutate()` if needed
synonyms <- all_wines_cleaned %>%
unnest(synonyms = strsplit(synonyms, ", ")) %>% # split the synonyms into multiple rows
rename(variety = synonyms) %>%
mutate(
variety = gsub("\\.", "", variety), # remove periods
variety = gsub("\\s*\\([^\\)]+\\)", "", variety), # remove brackets and anything within
variety = gsub("\\s*\\[[^\\)]+\\]", "", variety) # same for square brackets
) %>%
select(variety, colour) %>%
anti_join(common_names, by = "variety") # remove synonyms if we have a common name
#> Warning: unnest() has a new interface. See ?unnest for details.
#> Try `df %>% unnest(c(synonyms))`, with `mutate()` if needed
variety_colours <- rbind(common_names, synonyms) %>%
distinct %>%
arrange(variety)
variety_colours %>% head
#> # A tibble: 6 x 2
#> variety colour
#> <chr> <chr>
#> 1 " barbera dolce" red
#> 2 " cosses barbusen" red
#> 3 " limberger blauer" red
#> 4 "22 a baco" white
#> 5 "abbondosa" white
#> 6 "abboudossa" whiteThe end result is 8469 rows, with plenty of repeated entries to accommodate for multiple names or variations in spelling.
Joining the colour data
Now we join the colours with the wine data. If there are any missing values, we can attempt to fill them in based on obvious clues in the variety (eg. a “Red blend” can safely be assumed to be a red wine). We’re going to repeat this join as we iteratively improve the variety_colours data, so we’ll define it as a function.
join_with_variety_colours <- function(wine, variety_colours) {
wine %>%
left_join(
variety_colours %>% select(variety, colour),
by = "variety"
) %>%
mutate(
colour = case_when(
!is.na(colour) ~ colour,
grepl("sparkling", variety, ignore.case = TRUE) ~ "white",
grepl("champagne", variety, ignore.case = TRUE) ~ "white",
grepl("red", variety, ignore.case = TRUE) ~ "red",
grepl("white", variety, ignore.case = TRUE) ~ "white",
grepl("rosé", variety, ignore.case = TRUE) ~ "rosé",
grepl("rose", variety, ignore.case = TRUE) ~ "rosé"
)
)
}
wine_colours <- wine %>% join_with_variety_colours(variety_colours)
plot_wine_colours <- function(wine_colours) {
wine_colours %>%
ggplot(aes(x = colour, fill = colour)) +
geom_bar() +
scale_fill_manual(values = c(
"red" = red_wine_colour,
"white" = white_wine_colour,
"rosé" = rose_wine_colour),
na.value = "grey"
) +
ggtitle("Wine colours") +
theme(legend.position="none")
}
plot_wine_colours(wine_colours)
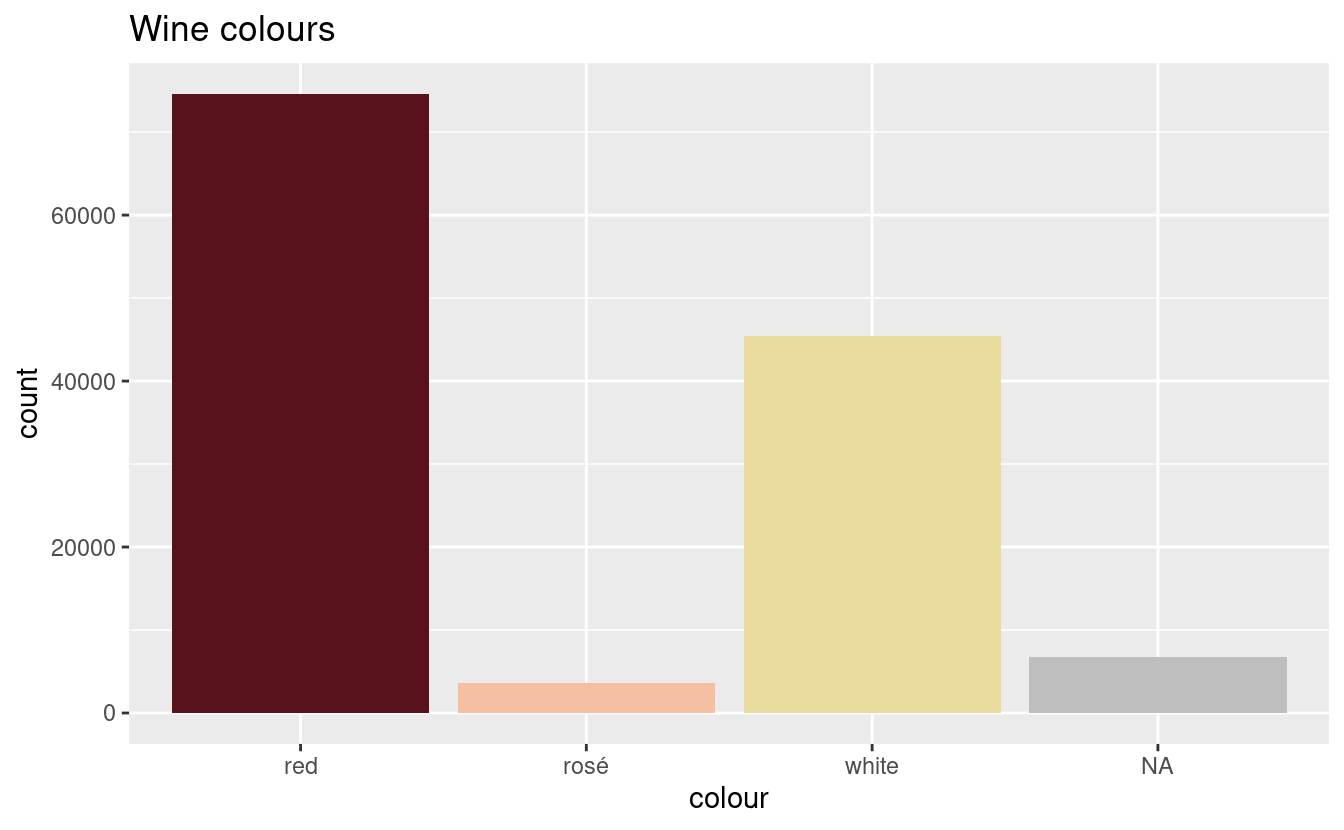
All but 6734 wines have been classified. We still have some colours missing, but first we consider the wines that have been classified as multiple colours:
wine_colours %>%
distinct(variety, colour) %>%
count(variety) %>%
filter(n > 1)
#> # A tibble: 4 x 2
#> variety n
#> <chr> <int>
#> 1 alicante 2
#> 2 grignolino 2
#> 3 malvasia fina 2
#> 4 sauvignon 2We use web searches to manually classify the varieties based on the colour of the wine that is most often produced from them.
variety_colours <- variety_colours %>%
filter(!(variety == "alicante" & colour != "red")) %>%
filter(!(variety == "grignolino" & colour != "red")) %>%
filter(!(variety == "malvasia fina" & colour != "white")) %>% # rarely red
filter(!(variety == "sauvignon" & colour != "white"))The below suggests that blends are not being classified:
wine_colours %>%
filter(is.na(colour)) %>%
count(variety, sort = TRUE) %>%
head(10)
#> # A tibble: 10 x 2
#> variety n
#> <chr> <int>
#> 1 port 668
#> 2 corvina, rondinella, molinara 619
#> 3 tempranillo blend 588
#> 4 carmenère 575
#> 5 meritage 260
#> 6 g-s-m 181
#> 7 mencía 178
#> 8 cabernet sauvignon-merlot 117
#> 9 nerello mascalese 117
#> 10 rosato 103We operate under the assumption that if multiple wines are listed, the first wine determines the colour. For example, cabernet is red and sauvignon is white, but cabernet sauvignon is red. We try to classify the unclassified wines again but using only the first word in their varieties. We split the variety by either spaces or dashes.
blend_colours <-
wine_colours %>%
filter(is.na(colour)) %>%
select(variety) %>%
rowwise %>%
mutate(first_variety = unlist(strsplit(variety, "\\-|\\ | "))[1]) %>%
merge(variety_colours, by.x = "first_variety", by.y = "variety") %>%
select(variety, colour) %>%
distinctNow we can rebuild the wine colours using these new blend results:
wine_colours <- wine %>% join_with_variety_colours(
rbind(variety_colours, blend_colours)
)
plot_wine_colours(wine_colours)
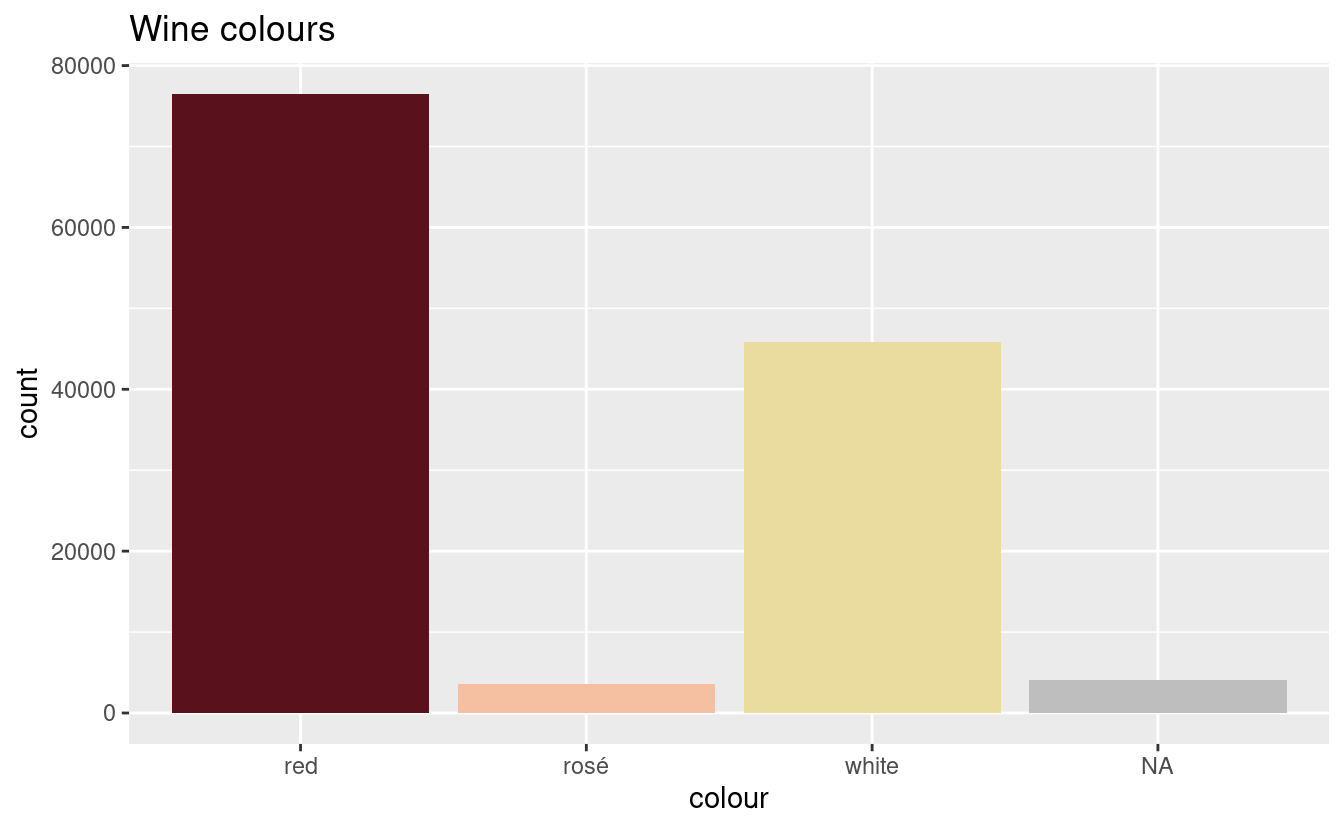
All but 4091 wines have been classified. This is an improvement, but we still have to classify the rest.
Manual classifications
We manually classify the remaining 154 varieties using web searches or the descriptions (reviews) associated with the wines.
manual_colours <- "manually_classified.csv" %>% read_csv
#> Parsed with column specification:
#> cols(
#> variety = col_character(),
#> colour = col_character()
#> )
wine_colours <- wine %>% join_with_variety_colours(
rbind(variety_colours, blend_colours, manual_colours)
)
plot_wine_colours(wine_colours)
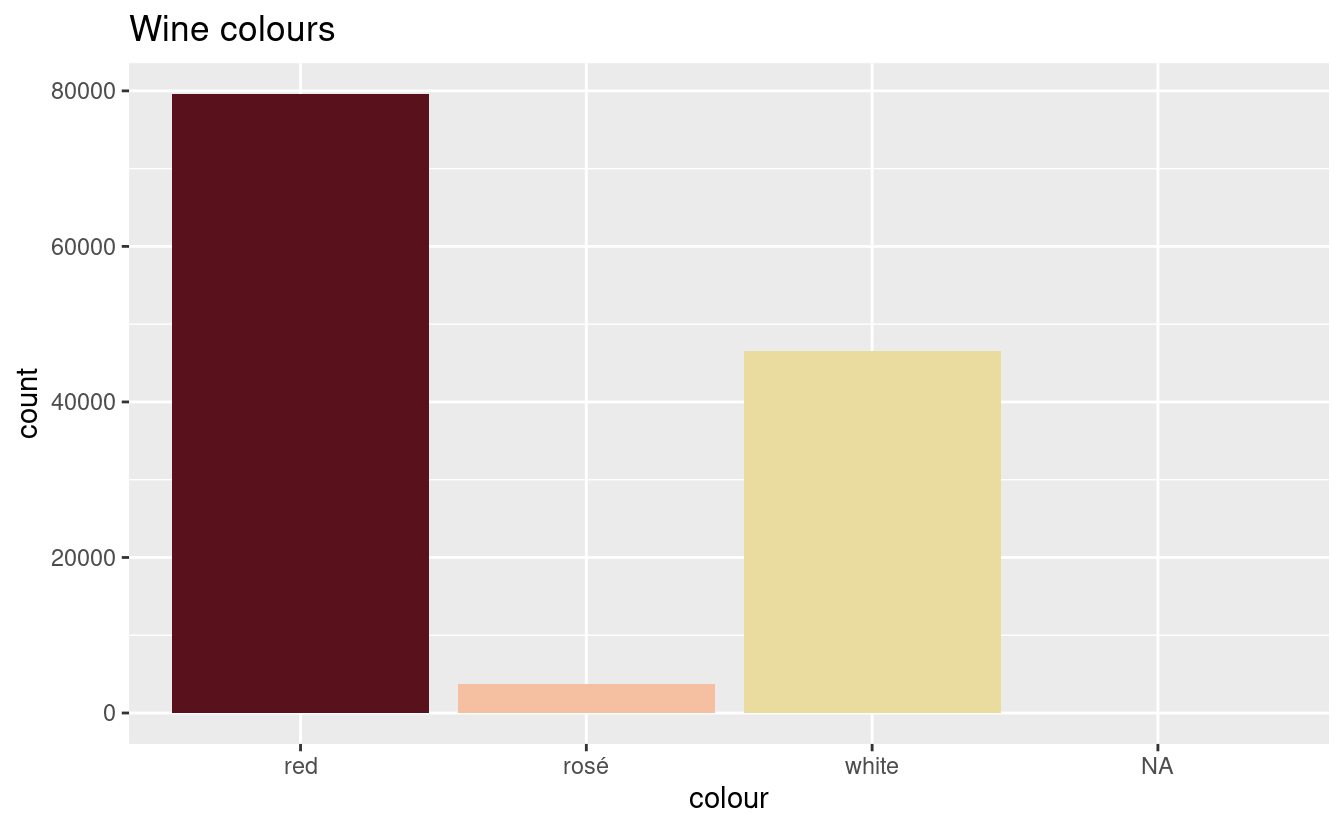
And we’re there! As I said earlier, this is a somewhat aggressive classification. But we’ve got the most popular wines—the pinot noirs and the chardonnays—classified, and we can hope that any errors are only “kind of wrong” rather than “totally wrong”, and limited to the varieties that only appear once or twice.
Data sources
To avoid any potential licencing issues, I prefer not to post Kaggle data directly here. I encourage you to download the csv directly from Kaggle. This will require a (free) Kaggle account. I’ve renamed the file here to wine_reviews.csv, but otherwise the data is unchanged before it is read. Other data used here:
- My manual classification of variety colours: manually_classified.csv
- The final outcome, giving just varieties and colours: variety_colours.csv
The header image at the top of this page is in the public domain.
devtools::session_info()
#> ─ Session info ───────────────────────────────────────────────────────────────
#> setting value
#> version R version 4.0.0 (2020-04-24)
#> os Ubuntu 20.04 LTS
#> system x86_64, linux-gnu
#> ui X11
#> language en_AU:en
#> collate en_AU.UTF-8
#> ctype en_AU.UTF-8
#> tz Australia/Melbourne
#> date 2020-06-13
#>
#> ─ Packages ───────────────────────────────────────────────────────────────────
#> package * version date lib source
#> assertthat 0.2.1 2019-03-21 [1] CRAN (R 4.0.0)
#> backports 1.1.7 2020-05-13 [1] CRAN (R 4.0.0)
#> broom 0.5.6 2020-04-20 [1] CRAN (R 4.0.0)
#> callr 3.4.3 2020-03-28 [1] CRAN (R 4.0.0)
#> cellranger 1.1.0 2016-07-27 [1] CRAN (R 4.0.0)
#> cli 2.0.2 2020-02-28 [1] CRAN (R 4.0.0)
#> codetools 0.2-16 2018-12-24 [4] CRAN (R 4.0.0)
#> colorspace 1.4-1 2019-03-18 [1] CRAN (R 4.0.0)
#> crayon 1.3.4 2017-09-16 [1] CRAN (R 4.0.0)
#> curl 4.3 2019-12-02 [1] CRAN (R 4.0.0)
#> DBI 1.1.0 2019-12-15 [1] CRAN (R 4.0.0)
#> dbplyr 1.4.3 2020-04-19 [1] CRAN (R 4.0.0)
#> desc 1.2.0 2018-05-01 [1] CRAN (R 4.0.0)
#> devtools 2.3.0 2020-04-10 [1] CRAN (R 4.0.0)
#> digest 0.6.25 2020-02-23 [1] CRAN (R 4.0.0)
#> downlit 0.0.0.9000 2020-06-12 [1] Github (r-lib/downlit@87fb1af)
#> dplyr * 0.8.5 2020-03-07 [1] CRAN (R 4.0.0)
#> ellipsis 0.3.1 2020-05-15 [1] CRAN (R 4.0.0)
#> evaluate 0.14 2019-05-28 [1] CRAN (R 4.0.0)
#> fansi 0.4.1 2020-01-08 [1] CRAN (R 4.0.0)
#> farver 2.0.3 2020-01-16 [1] CRAN (R 4.0.0)
#> forcats * 0.5.0 2020-03-01 [1] CRAN (R 4.0.0)
#> fs 1.4.1 2020-04-04 [1] CRAN (R 4.0.0)
#> generics 0.0.2 2018-11-29 [1] CRAN (R 4.0.0)
#> ggplot2 * 3.3.0 2020-03-05 [1] CRAN (R 4.0.0)
#> glue 1.4.1 2020-05-13 [1] CRAN (R 4.0.0)
#> gtable 0.3.0 2019-03-25 [1] CRAN (R 4.0.0)
#> haven 2.2.0 2019-11-08 [1] CRAN (R 4.0.0)
#> highr 0.8 2019-03-20 [1] CRAN (R 4.0.0)
#> hms 0.5.3 2020-01-08 [1] CRAN (R 4.0.0)
#> htmltools 0.4.0 2019-10-04 [1] CRAN (R 4.0.0)
#> httr 1.4.1 2019-08-05 [1] CRAN (R 4.0.0)
#> hugodown 0.0.0.9000 2020-06-12 [1] Github (r-lib/hugodown@6812ada)
#> jsonlite 1.6.1 2020-02-02 [1] CRAN (R 4.0.0)
#> kableExtra * 1.1.0 2019-03-16 [1] CRAN (R 4.0.0)
#> knitr 1.28 2020-02-06 [1] CRAN (R 4.0.0)
#> labeling 0.3 2014-08-23 [1] CRAN (R 4.0.0)
#> lattice 0.20-41 2020-04-02 [4] CRAN (R 4.0.0)
#> lifecycle 0.2.0 2020-03-06 [1] CRAN (R 4.0.0)
#> lubridate 1.7.8 2020-04-06 [1] CRAN (R 4.0.0)
#> magrittr 1.5 2014-11-22 [1] CRAN (R 4.0.0)
#> memoise 1.1.0.9000 2020-05-09 [1] Github (hadley/memoise@4aefd9f)
#> modelr 0.1.6 2020-02-22 [1] CRAN (R 4.0.0)
#> munsell 0.5.0 2018-06-12 [1] CRAN (R 4.0.0)
#> nlme 3.1-145 2020-03-04 [4] CRAN (R 4.0.0)
#> pillar 1.4.4 2020-05-05 [1] CRAN (R 4.0.0)
#> pkgbuild 1.0.7 2020-04-25 [1] CRAN (R 4.0.0)
#> pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.0.0)
#> pkgload 1.0.2 2018-10-29 [1] CRAN (R 4.0.0)
#> prettyunits 1.1.1 2020-01-24 [1] CRAN (R 4.0.0)
#> processx 3.4.2 2020-02-09 [1] CRAN (R 4.0.0)
#> ps 1.3.3 2020-05-08 [1] CRAN (R 4.0.0)
#> purrr * 0.3.4 2020-04-17 [1] CRAN (R 4.0.0)
#> R6 2.4.1 2019-11-12 [1] CRAN (R 4.0.0)
#> Rcpp 1.0.4.6 2020-04-09 [1] CRAN (R 4.0.0)
#> readr * 1.3.1 2018-12-21 [1] CRAN (R 4.0.0)
#> readxl 1.3.1 2019-03-13 [1] CRAN (R 4.0.0)
#> remotes 2.1.1 2020-02-15 [1] CRAN (R 4.0.0)
#> reprex 0.3.0 2019-05-16 [1] CRAN (R 4.0.0)
#> rlang 0.4.6 2020-05-02 [1] CRAN (R 4.0.0)
#> rmarkdown 2.2.3 2020-06-12 [1] Github (rstudio/rmarkdown@4ee96c8)
#> rprojroot 1.3-2 2018-01-03 [1] CRAN (R 4.0.0)
#> rstudioapi 0.11 2020-02-07 [1] CRAN (R 4.0.0)
#> rvest * 0.3.5 2019-11-08 [1] CRAN (R 4.0.0)
#> scales 1.1.0 2019-11-18 [1] CRAN (R 4.0.0)
#> selectr 0.4-2 2019-11-20 [1] CRAN (R 4.0.0)
#> sessioninfo 1.1.1 2018-11-05 [1] CRAN (R 4.0.0)
#> stringi 1.4.6 2020-02-17 [1] CRAN (R 4.0.0)
#> stringr * 1.4.0 2019-02-10 [1] CRAN (R 4.0.0)
#> testthat 2.3.2 2020-03-02 [1] CRAN (R 4.0.0)
#> tibble * 3.0.1 2020-04-20 [1] CRAN (R 4.0.0)
#> tidyr * 1.0.2 2020-01-24 [1] CRAN (R 4.0.0)
#> tidyselect 1.0.0 2020-01-27 [1] CRAN (R 4.0.0)
#> tidyverse * 1.3.0 2019-11-21 [1] CRAN (R 4.0.0)
#> usethis 1.6.1 2020-04-29 [1] CRAN (R 4.0.0)
#> vctrs 0.3.1 2020-06-05 [1] CRAN (R 4.0.0)
#> viridisLite 0.3.0 2018-02-01 [1] CRAN (R 4.0.0)
#> webshot 0.5.2 2019-11-22 [1] CRAN (R 4.0.0)
#> withr 2.2.0 2020-04-20 [1] CRAN (R 4.0.0)
#> xfun 0.14 2020-05-20 [1] CRAN (R 4.0.0)
#> xml2 * 1.3.2 2020-04-23 [1] CRAN (R 4.0.0)
#> yaml 2.2.1 2020-02-01 [1] CRAN (R 4.0.0)
#>
#> [1] /home/mdneuzerling/R/x86_64-pc-linux-gnu-library/4.0
#> [2] /usr/local/lib/R/site-library
#> [3] /usr/lib/R/site-library
#> [4] /usr/lib/R/library