After I posted my efforts to use MLflow to serve a model with R, I was worried that people may think I don’t like MLflow. I want to declare this: MLflow is awesome. I’ll showcase its model tracking features, and how to integrate them into a tidymodels model.
The Tracking component of MLflow can be used to record parameters, metrics and artifacts every time a model is trained. All of this information is presented in a very nice user interface. I’ll also finish off here by demonstrating how to serve a model created with Tidymodels, which I find much easier than serving a model created with arbitrary code.
Prepare a model
I’ll prepare a model using the recent TidyTuesday coffee data. This is the same process I followed in my last post, except I’ll stop short of fitting and evaluating the model so I can track those steps with MLflow.
coffee <- invisible(tidytuesdayR::tt_load(2020, week = 28)$coffee)
#>
#> Downloading file 1 of 1: `coffee_ratings.csv`
coffee_split <- initial_split(coffee, prop = 0.8)
coffee_train <- training(coffee_split)
coffee_test <- testing(coffee_split)
coffee_recipe <- recipe(coffee_train) %>%
update_role(everything(), new_role = "support") %>%
update_role(cupper_points, new_role = "outcome") %>%
update_role(
variety, processing_method, country_of_origin,
aroma, flavor, aftertaste, acidity, sweetness, altitude_mean_meters,
new_role = "predictor"
) %>%
step_string2factor(all_nominal(), -all_outcomes()) %>%
step_knnimpute(country_of_origin,
impute_with = imp_vars(
in_country_partner, company, region, farm_name, certification_body
)
) %>%
step_knnimpute(altitude_mean_meters,
impute_with = imp_vars(
in_country_partner, company, region, farm_name, certification_body,
country_of_origin
)
) %>%
step_unknown(variety, processing_method, new_level = "Unknown") %>%
step_other(country_of_origin, threshold = 0.01) %>%
step_other(processing_method, threshold = 0.10) %>%
step_other(variety, threshold = 0.10) %>%
step_normalize(all_numeric(), -all_outcomes())
coffee_model <- rand_forest(trees = tune(), mtry = tune()) %>%
set_engine("ranger") %>%
set_mode("regression")
coffee_workflow <- workflows::workflow() %>%
add_recipe(coffee_recipe) %>%
add_model(coffee_model)
coffee_grid <- expand_grid(mtry = 3:5, trees = seq(500, 1500, by = 200))
coffee_grid_results <- coffee_workflow %>%
tune_grid(resamples <- vfold_cv(coffee_train, v = 5), grid = coffee_grid)
hyperparameters <- coffee_grid_results %>%
select_by_pct_loss(metric = "rmse", limit = 5, trees)coffee_workflow
#> ══ Workflow ════════════════════════════════════════════════════════════════════════════════════════════════════════════
#> Preprocessor: Recipe
#> Model: rand_forest()
#>
#> ── Preprocessor ────────────────────────────────────────────────────────────────────────────────────────────────────────
#> 8 Recipe Steps
#>
#> ● step_string2factor()
#> ● step_knnimpute()
#> ● step_knnimpute()
#> ● step_unknown()
#> ● step_other()
#> ● step_other()
#> ● step_other()
#> ● step_normalize()
#>
#> ── Model ───────────────────────────────────────────────────────────────────────────────────────────────────────────────
#> Random Forest Model Specification (regression)
#>
#> Main Arguments:
#> mtry = tune()
#> trees = tune()
#>
#> Computational engine: rangerAutomatic tracking with workflows
MLflow tracking is organised around experiments and runs. Broadly speaking, an experiment is a project, whereas a run is a process in which a model is trained and evaluated. But these categories could be repurposed for anything1.
In each run the user can record parameters and metrics. Parameters and metrics are both arbitrary key-value pairs that could be used for anything. In my coffee example, I might have parameters trees: 500 and mtry: 3. My metric might be mae: 0.2. I would log this information with mlflow_log_param("trees", 500) or mlflow_log_metric("mae", 0.2). That’s all I need to do, and MLflow takes care of the rest.
I’ll be storing all of this information locally, with MLflow recording information in the mlruns directory in my working directory. Alternatively, I could host my tracking information remotely, for example in a database.
Certain kinds of Python model flavours, such as Tensorflow, have autotracking in which parameters and metrics are automatically recorded. I’ll try and implement a rough version of this for a Tidymodels workflow. I’m aiming for functions here that let me record parameters and metrics for any type of model implemented through as a Tidymodels workflow, so that I can change from a random forest to a linear model without adjusting my MLflow code.
I’ll start with a function for logging model hyperparameters as MLflow parameters. This function will only log hyperparameters set by the user, since the default values have a NULL expression, but I think that this approach makes sense. It also passes on the input workflow unmodified, so it’s pipe-friendly:
log_workflow_parameters <- function(workflow) {
# Would help to have a check here: has this workflow been finalised?
# It may be sufficient to check that the arg quosures carry no environments.
spec <- workflows::pull_workflow_spec(workflow)
parameter_names <- names(spec$args)
parameter_values <- lapply(spec$args, rlang::get_expr)
for (i in seq_along(spec$args)) {
parameter_name <- parameter_names[[i]]
parameter_value <- parameter_values[[i]]
if (!is.null(parameter_value)) {
mlflow_log_param(parameter_name, parameter_value)
}
}
workflow
}Now I’ll do the same for metrics. The input to this function will be a metrics tibble produced by the yardstick package, which is a component of tidymodels:
log_metrics <- function(metrics, estimator = "standard") {
metrics %>% filter(.estimator == estimator) %>% pmap(
function(.metric, .estimator, .estimate) {
mlflow_log_metric(.metric, .estimate)
}
)
metrics
}Packaging workflows is pretty easy
There’s one last component I need to make this work. Apart from parameters and metrics, I can also store artifacts with each run. These are usually models, but could be anything. MLflow supports exporting models with the carrier::crate function. This is a tricky function to use, since the user must comprehensively list their dependencies. For a workflow with a recipe, it’s a lot easier. All of the preprocessing is contained within the recipe, and the fitted workflow object contains this.
# I haven't yet defined fitted_coffee_model, so I won't run this
crated_model <- carrier::crate(
function(x) workflows:::predict.workflow(fitted_coffee_model, x),
fitted_coffee_model = fitted_coffee_model
)MLflow tracks artifacts along with parameters and metrics. These are any files associated with the run, including models. I think the mlflow_log_model function should be used here, but it doesn’t work for me. Instead I save the crated model with mlflow_save_model and log it with mlflow_log_artifact.
Tracking a model training run with MLflow
I’ll set my experiment as coffee. I only need to do this once per session:
mlflow_set_experiment(experiment_name = "coffee")To actually do an MLflow run, I wrap my model training and evaluation code in a with(mlflow_start_run(), ...) block. I insert my logging functions into my training code:
with(mlflow_start_run(), {
fitted_coffee_model <- coffee_workflow %>%
finalize_workflow(hyperparameters) %>%
log_workflow_parameters() %>%
fit(coffee_train)
metrics <- fitted_coffee_model %>%
predict(coffee_test) %>%
metric_set(rmse, mae, rsq)(coffee_test$cupper_points, .pred) %>%
log_metrics()
crated_model <- carrier::crate(
function(x) workflows:::predict.workflow(fitted_coffee_model, x),
fitted_coffee_model = fitted_coffee_model
)
mlflow_save_model(crated_model, here::here("models"))
mlflow_log_artifact(here::here("models", "crate.bin"))
})
#> 2020/08/17 09:09:28 INFO mlflow.store.artifact.cli: Logged artifact from local file /home/mdneuzerling/mdneuzerling.com/models/crate.bin to artifact_path=None
#>
#> Root URI: /home/mdneuzerling/Documents/coffee/mlruns/1/d2bdcbdf3e9849598b393951fa69214c/artifactsI can see all the run information, stored as plain text, appearing in my mlruns directory now:
fs::dir_tree("mlruns/1/f26b040f80244b00882d2925ebdc8396/")
#> mlruns/1/f26b040f80244b00882d2925ebdc8396/
#> ├── artifacts
#> │ └── crate.bin
#> ├── meta.yaml
#> ├── metrics
#> │ ├── mae
#> │ ├── rmse
#> │ └── rsq
#> ├── params
#> │ ├── mtry
#> │ └── trees
#> └── tags
#> ├── mlflow.source.name
#> ├── mlflow.source.type
#> └── mlflow.userI have a quibble here: I create an experiment with a name, but MLflow identifies experiments with an integer ID. It would be great if I could write with(mlflow_start_run(experiment_name = "coffee"), ...), but only the experiment_id is supported. It’s a minor point, but I’m not a fan of having that separate mlflow_set_experiment function there because it’s a state that I have to manage in a functional language. The other issue here is that while my collaborators and I might all be using the same experiment_name, we don’t know that we’ll be on the same experiment_id.
Viewing runs with the MLflow UI
MLflow comes with a gorgeous user interface for exploring previous model runs. I can run it with mlflow_ui and view it in my browser:
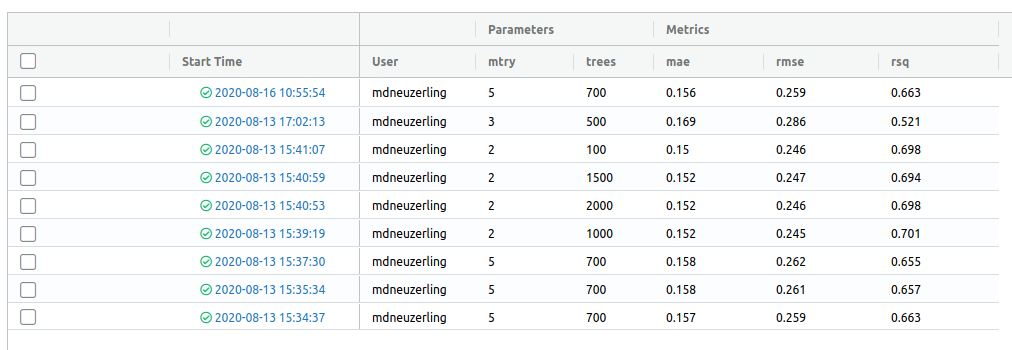
A word of warning: the model hyperparameters in this UI are placed directly next to the model metrics. The dashboard makes it look like I should be selecting the hyperparameters which reduce my error metrics. I can’t use the same test data to select my hyperparameters and evaluate my model, because this leaks information from the test set to the model. But the UI places the hyperparameters next to the metrics, making it look as though I should be selecting the hyperparameters with the best metrics.
This isn’t a flaw of MLflow, though. One thing I could do here to make the data leakage trap easier to avoid is to log the “cross-validation RMSE” that was used to select the hyperparameters. If I include this is a column before the other metrics, it makes it clear what I used to select those trees and mtry values.
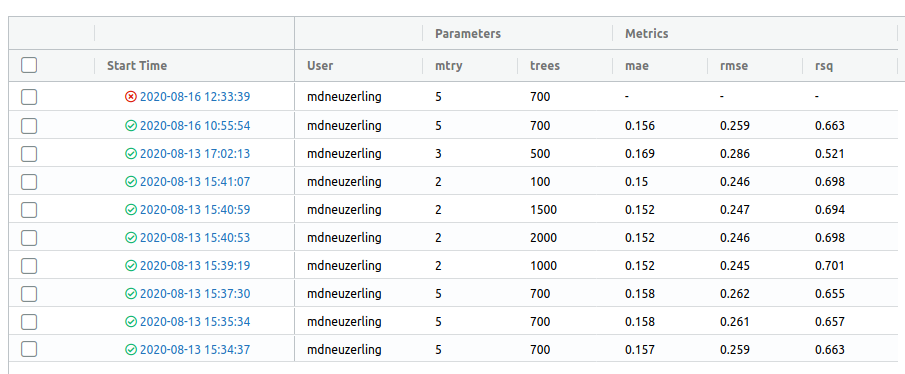
What I really like about this use of MLflow is that if there’s an error in my model training run, MLflow will pick that up and record what it can, and label the run as an error in the UI:
Serving coffee
MLflow Models is the MLflow component used for serving exported models as APIs. I can serve my coffee model that I exported earlier with mlflow_rfunc_serve("models"). Since I’m overwriting this directory with each run (before I log the artifact with the run), this will be the last model to have been exported. This command will open up a Swagger UI, so I don’t have to mess around with piecing together a HTTP request.
To test this, I can try to predict the results of a random data point in the test set. Note the na = "string" argument here, since missing values will be incorrectly represented without it:
coffee_test %>% select(-cupper_points) %>% sample_n(1) %>% jsonlite::toJSON(na = "string")`
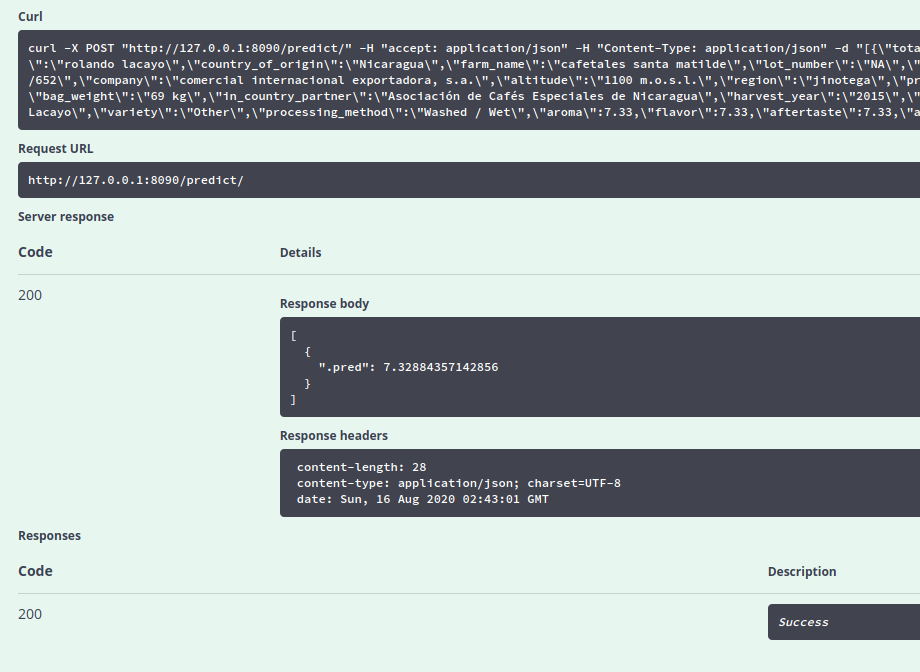
It seems as though this method only serves one prediction at a time, even if multiple rows are provided.
I could also have served this model through the command line with mlflow models serve -m models/.
tidymodels works really well with MLflow
tidymodels presents an excellent opportunity to make life a bit easier for R users who want to take advantage of MLflow.
MLflow exports models through patterns known as flavours. There are many flavour available for Python, but only crate and keras for R. crate does have the advantage of supporting arbitrary R code, however.
A tidymodels flavour for workflows/parsnip models could be implemented through the crate flavour, as I’ve done above, or separately. This isn’t as tricky as exporting arbitrary R code, since all of the preprocessing is done through the recipes package.
The tidymodels framework also opens up the possibility of autologging. I’ve implemented some functions above that accomplish this, but they’re a little rough. With a bit of polish, users could take advantage of MLflow with very little effort.
devtools::session_info()
#> ─ Session info ───────────────────────────────────────────────────────────────
#> setting value
#> version R version 4.0.0 (2020-04-24)
#> os Ubuntu 20.04.1 LTS
#> system x86_64, linux-gnu
#> ui X11
#> language en_AU:en
#> collate en_AU.UTF-8
#> ctype en_AU.UTF-8
#> tz Australia/Melbourne
#> date 2020-08-17
#>
#> ─ Packages ───────────────────────────────────────────────────────────────────
#> package * version date lib source
#> askpass 1.1 2019-01-13 [1] CRAN (R 4.0.0)
#> assertthat 0.2.1 2019-03-21 [1] CRAN (R 4.0.0)
#> backports 1.1.8 2020-06-17 [1] CRAN (R 4.0.0)
#> base64enc 0.1-3 2015-07-28 [1] CRAN (R 4.0.0)
#> blob 1.2.1 2020-01-20 [1] CRAN (R 4.0.0)
#> broom * 0.7.0 2020-07-09 [1] CRAN (R 4.0.0)
#> callr 3.4.3 2020-03-28 [1] CRAN (R 4.0.0)
#> carrier 0.1.0 2018-10-16 [1] CRAN (R 4.0.0)
#> cellranger 1.1.0 2016-07-27 [1] CRAN (R 4.0.0)
#> class 7.3-17 2020-04-26 [4] CRAN (R 4.0.0)
#> cli 2.0.2 2020-02-28 [1] CRAN (R 4.0.0)
#> codetools 0.2-16 2018-12-24 [4] CRAN (R 4.0.0)
#> colorspace 1.4-1 2019-03-18 [1] CRAN (R 4.0.0)
#> crayon 1.3.4 2017-09-16 [1] CRAN (R 4.0.0)
#> curl 4.3 2019-12-02 [1] CRAN (R 4.0.0)
#> DBI 1.1.0 2019-12-15 [1] CRAN (R 4.0.0)
#> dbplyr 1.4.4 2020-05-27 [1] CRAN (R 4.0.0)
#> desc 1.2.0 2018-05-01 [1] CRAN (R 4.0.0)
#> devtools 2.3.0 2020-04-10 [1] CRAN (R 4.0.0)
#> dials * 0.0.8 2020-07-08 [1] CRAN (R 4.0.0)
#> DiceDesign 1.8-1 2019-07-31 [1] CRAN (R 4.0.0)
#> digest 0.6.25 2020-02-23 [1] CRAN (R 4.0.0)
#> downlit 0.0.0.9000 2020-07-25 [1] Github (r-lib/downlit@ed969d0)
#> dplyr * 1.0.1 2020-07-31 [1] CRAN (R 4.0.0)
#> ellipsis 0.3.1 2020-05-15 [1] CRAN (R 4.0.0)
#> evaluate 0.14 2019-05-28 [1] CRAN (R 4.0.0)
#> fansi 0.4.1 2020-01-08 [1] CRAN (R 4.0.0)
#> forcats * 0.5.0 2020-03-01 [1] CRAN (R 4.0.0)
#> foreach 1.5.0 2020-03-30 [1] CRAN (R 4.0.0)
#> forge 0.2.0 2019-02-26 [1] CRAN (R 4.0.0)
#> fs 1.5.0 2020-07-31 [1] CRAN (R 4.0.0)
#> furrr 0.1.0 2018-05-16 [1] CRAN (R 4.0.0)
#> future 1.17.0 2020-04-18 [1] CRAN (R 4.0.0)
#> generics 0.0.2 2018-11-29 [1] CRAN (R 4.0.0)
#> ggplot2 * 3.3.2.9000 2020-08-07 [1] Github (tidyverse/ggplot2@6d91349)
#> git2r 0.27.1 2020-05-03 [1] CRAN (R 4.0.0)
#> globals 0.12.5 2019-12-07 [1] CRAN (R 4.0.0)
#> glue 1.4.1 2020-05-13 [1] CRAN (R 4.0.0)
#> gower 0.2.2 2020-06-23 [1] CRAN (R 4.0.0)
#> GPfit 1.0-8 2019-02-08 [1] CRAN (R 4.0.0)
#> gtable 0.3.0 2019-03-25 [1] CRAN (R 4.0.0)
#> hardhat 0.1.4 2020-07-02 [1] CRAN (R 4.0.0)
#> haven 2.2.0 2019-11-08 [1] CRAN (R 4.0.0)
#> here 0.1 2017-05-28 [1] CRAN (R 4.0.0)
#> hms 0.5.3 2020-01-08 [1] CRAN (R 4.0.0)
#> htmltools 0.5.0 2020-06-16 [1] CRAN (R 4.0.0)
#> httpuv 1.5.2 2019-09-11 [1] CRAN (R 4.0.0)
#> httr 1.4.2 2020-07-20 [1] CRAN (R 4.0.0)
#> hugodown 0.0.0.9000 2020-08-13 [1] Github (r-lib/hugodown@2af491d)
#> infer * 0.5.3 2020-07-14 [1] CRAN (R 4.0.0)
#> ini 0.3.1 2018-05-20 [1] CRAN (R 4.0.0)
#> ipred 0.9-9 2019-04-28 [1] CRAN (R 4.0.0)
#> iterators 1.0.12 2019-07-26 [1] CRAN (R 4.0.0)
#> jsonlite 1.7.0 2020-06-25 [1] CRAN (R 4.0.0)
#> knitr 1.29 2020-06-23 [1] CRAN (R 4.0.0)
#> later 1.1.0.1 2020-06-05 [1] CRAN (R 4.0.0)
#> lattice 0.20-41 2020-04-02 [4] CRAN (R 4.0.0)
#> lava 1.6.7 2020-03-05 [1] CRAN (R 4.0.0)
#> lhs 1.0.2 2020-04-13 [1] CRAN (R 4.0.0)
#> lifecycle 0.2.0 2020-03-06 [1] CRAN (R 4.0.0)
#> listenv 0.8.0 2019-12-05 [1] CRAN (R 4.0.0)
#> lubridate 1.7.9 2020-06-08 [1] CRAN (R 4.0.0)
#> magrittr 1.5 2014-11-22 [1] CRAN (R 4.0.0)
#> MASS 7.3-51.6 2020-04-26 [4] CRAN (R 4.0.0)
#> Matrix 1.2-18 2019-11-27 [4] CRAN (R 4.0.0)
#> memoise 1.1.0.9000 2020-05-09 [1] Github (hadley/memoise@4aefd9f)
#> mlflow * 1.10.0 2020-07-21 [1] CRAN (R 4.0.0)
#> modeldata * 0.0.2 2020-06-22 [1] CRAN (R 4.0.0)
#> modelr 0.1.6 2020-02-22 [1] CRAN (R 4.0.0)
#> munsell 0.5.0 2018-06-12 [1] CRAN (R 4.0.0)
#> nnet 7.3-14 2020-04-26 [4] CRAN (R 4.0.0)
#> openssl 1.4.2 2020-06-27 [1] CRAN (R 4.0.0)
#> parsnip * 0.1.2 2020-07-03 [1] CRAN (R 4.0.0)
#> pillar 1.4.6 2020-07-10 [1] CRAN (R 4.0.0)
#> pkgbuild 1.1.0 2020-07-13 [1] CRAN (R 4.0.0)
#> pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.0.0)
#> pkgload 1.1.0 2020-05-29 [1] CRAN (R 4.0.0)
#> plyr 1.8.6 2020-03-03 [1] CRAN (R 4.0.0)
#> prettyunits 1.1.1 2020-01-24 [1] CRAN (R 4.0.0)
#> pROC 1.16.2 2020-03-19 [1] CRAN (R 4.0.0)
#> processx 3.4.3 2020-07-05 [1] CRAN (R 4.0.0)
#> prodlim 2019.11.13 2019-11-17 [1] CRAN (R 4.0.0)
#> promises 1.1.1 2020-06-09 [1] CRAN (R 4.0.0)
#> ps 1.3.4 2020-08-11 [1] CRAN (R 4.0.0)
#> purrr * 0.3.4 2020-04-17 [1] CRAN (R 4.0.0)
#> R6 2.4.1 2019-11-12 [1] CRAN (R 4.0.0)
#> ranger 0.12.1 2020-01-10 [1] CRAN (R 4.0.0)
#> Rcpp 1.0.5 2020-07-06 [1] CRAN (R 4.0.0)
#> readr * 1.3.1 2018-12-21 [1] CRAN (R 4.0.0)
#> readxl 1.3.1 2019-03-13 [1] CRAN (R 4.0.0)
#> recipes * 0.1.13 2020-06-23 [1] CRAN (R 4.0.0)
#> remotes 2.1.1 2020-02-15 [1] CRAN (R 4.0.0)
#> reprex 0.3.0 2019-05-16 [1] CRAN (R 4.0.0)
#> reticulate 1.16 2020-05-27 [1] CRAN (R 4.0.0)
#> rlang 0.4.7 2020-07-09 [1] CRAN (R 4.0.0)
#> rmarkdown 2.3.3 2020-08-13 [1] Github (rstudio/rmarkdown@204aa41)
#> rpart 4.1-15 2019-04-12 [4] CRAN (R 4.0.0)
#> rprojroot 1.3-2 2018-01-03 [1] CRAN (R 4.0.0)
#> rsample * 0.0.7 2020-06-04 [1] CRAN (R 4.0.0)
#> rstudioapi 0.11 2020-02-07 [1] CRAN (R 4.0.0)
#> rvest 0.3.5 2019-11-08 [1] CRAN (R 4.0.0)
#> scales * 1.1.1 2020-05-11 [1] CRAN (R 4.0.0)
#> sessioninfo 1.1.1 2018-11-05 [1] CRAN (R 4.0.0)
#> stringi 1.4.6 2020-02-17 [1] CRAN (R 4.0.0)
#> stringr * 1.4.0 2019-02-10 [1] CRAN (R 4.0.0)
#> survival 3.1-12 2020-04-10 [4] CRAN (R 4.0.0)
#> swagger 3.9.2 2018-03-23 [1] CRAN (R 4.0.0)
#> testthat 2.3.2 2020-03-02 [1] CRAN (R 4.0.0)
#> tibble * 3.0.3 2020-07-10 [1] CRAN (R 4.0.0)
#> tidymodels * 0.1.1 2020-07-14 [1] CRAN (R 4.0.0)
#> tidyr * 1.1.1 2020-07-31 [1] CRAN (R 4.0.0)
#> tidyselect 1.1.0 2020-05-11 [1] CRAN (R 4.0.0)
#> tidyverse * 1.3.0 2019-11-21 [1] CRAN (R 4.0.0)
#> timeDate 3043.102 2018-02-21 [1] CRAN (R 4.0.0)
#> tune * 0.1.1 2020-07-08 [1] CRAN (R 4.0.0)
#> usethis 1.6.1 2020-04-29 [1] CRAN (R 4.0.0)
#> vctrs 0.3.2 2020-07-15 [1] CRAN (R 4.0.0)
#> withr 2.2.0 2020-04-20 [1] CRAN (R 4.0.0)
#> workflows * 0.1.2 2020-07-07 [1] CRAN (R 4.0.0)
#> xfun 0.16 2020-07-24 [1] CRAN (R 4.0.0)
#> xml2 1.3.2 2020-04-23 [1] CRAN (R 4.0.0)
#> yaml 2.2.1 2020-02-01 [1] CRAN (R 4.0.0)
#> yardstick * 0.0.7 2020-07-13 [1] CRAN (R 4.0.0)
#> zeallot 0.1.0 2018-01-28 [1] CRAN (R 4.0.0)
#>
#> [1] /home/mdneuzerling/R/x86_64-pc-linux-gnu-library/4.0
#> [2] /usr/local/lib/R/site-library
#> [3] /usr/lib/R/site-library
#> [4] /usr/lib/R/libraryHere’s an idea: use MLflow to track reports! Every report is an experiment, and every production of a report is a run.↩︎