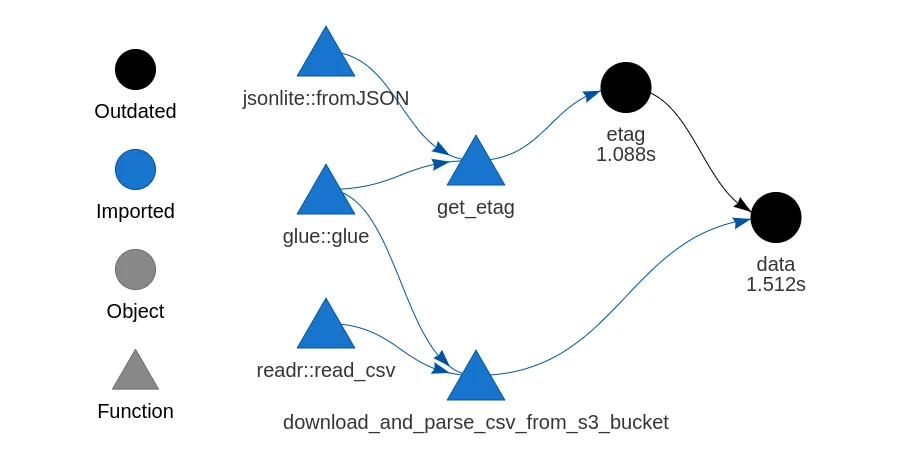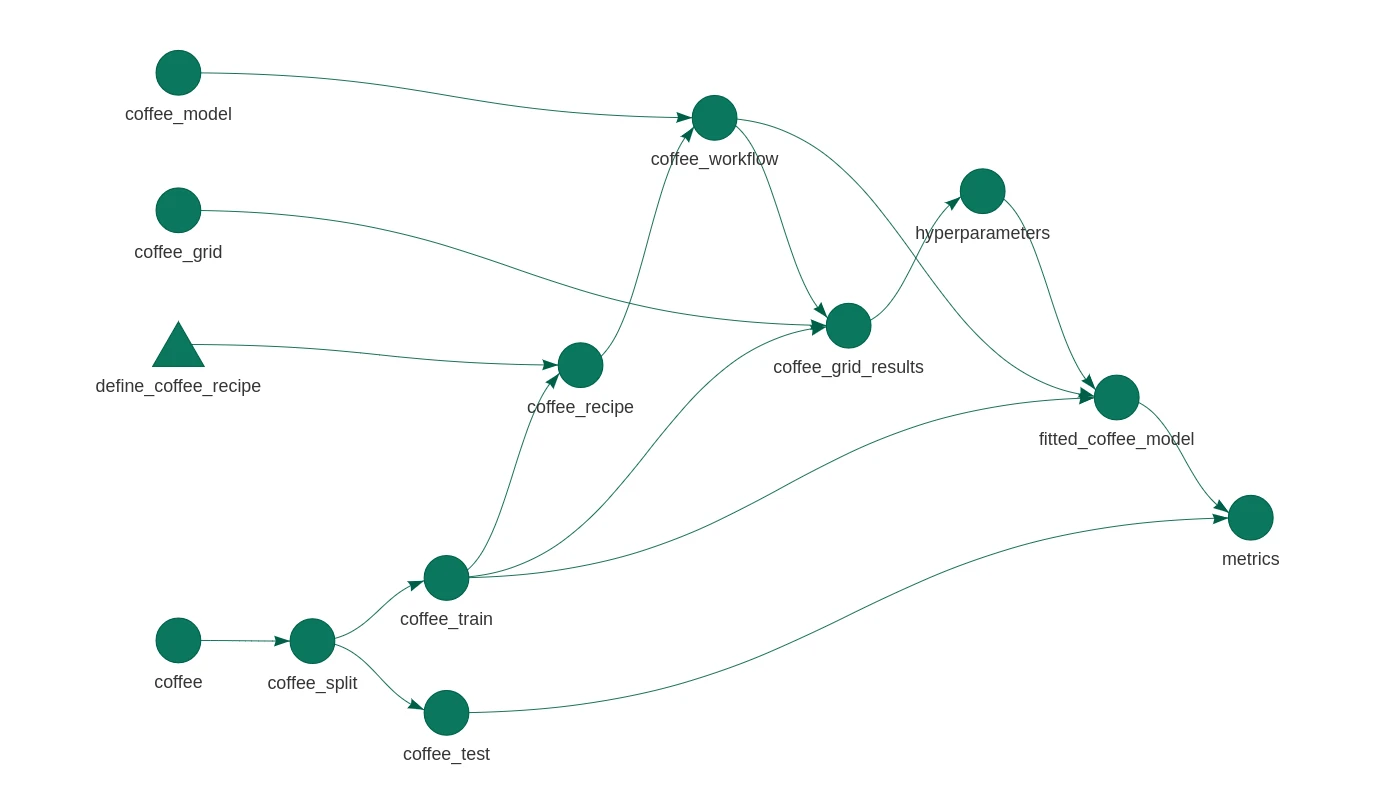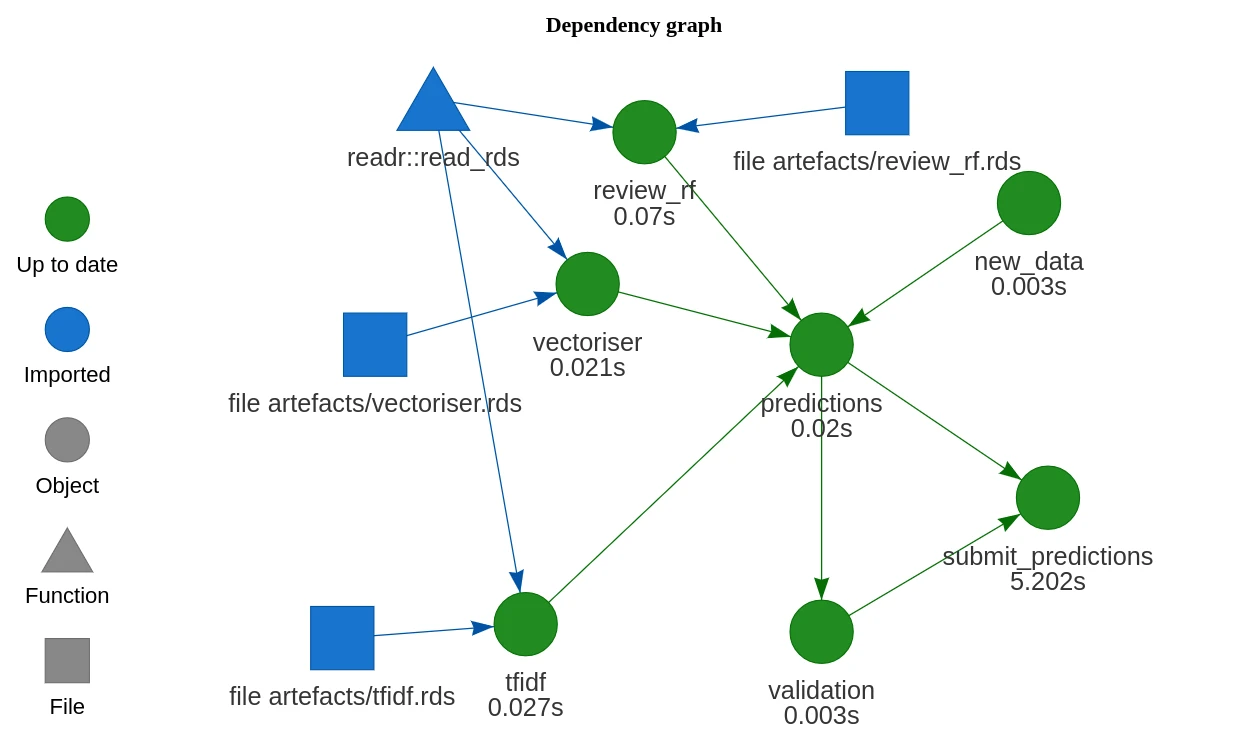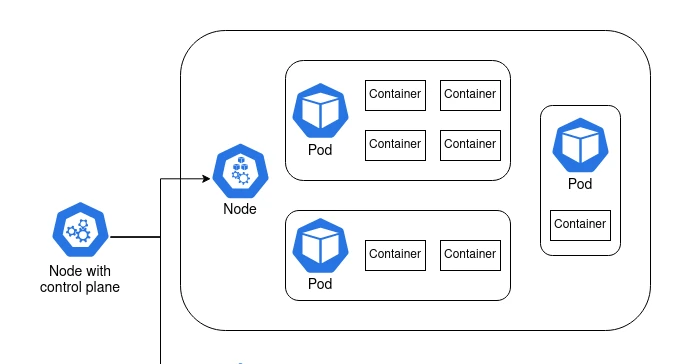
Hosting a Plumber API with Kubernetes
I've set myself an ambitious goal of building a Kubernetes cluster out of a couple of Raspberry Pis. This is pretty far out of my sphere of knowledge, so I have a lot to learn. I'll be writing some posts to publish my notes and journal my experience publicly. In this post I'll go through the basi......