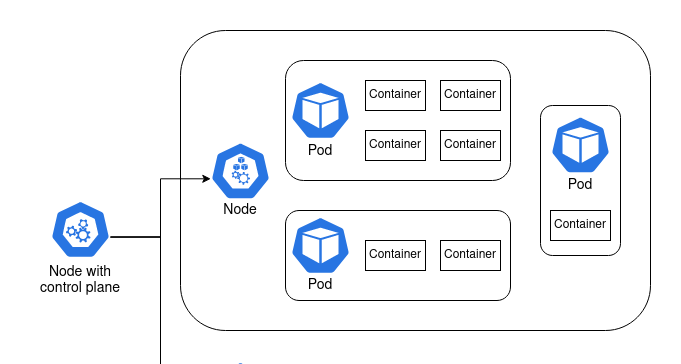
I’ve set myself an ambitious goal of building a Kubernetes cluster out of a couple of Raspberry Pis. This is pretty far out of my sphere of knowledge, so I have a lot to learn. I’ll be writing some posts to publish my notes and journal my experience publicly. In this post I’ll go through the basics of Kubernetes, and how I hosted a Plumber API in a Kubernetes cluster on Google Cloud Platform.
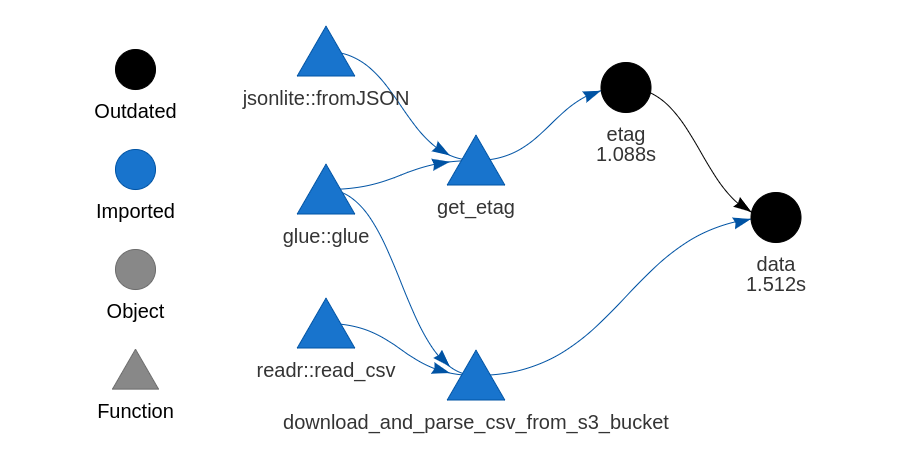
drake is a package for orchestrating R workflows. Suppose I have some data in S3 that I want to pull into R through a drake plan. In this post I’ll use the S3 object’s ETag to make drake only re-download the data if it’s changed.
This covers the scenario in which the object name in S3 stays the same. If I had, say, data being uploaded each day with an object name suffixed with the date, then I wouldn’t bother checking for any changes.
After I posted my efforts to use MLflow to serve a model with R, I was worried that people may think I don’t like MLflow. I want to declare this: MLflow is awesome. I’ll showcase its model tracking features, and how to integrate them into a tidymodels model.
The Tracking component of MLflow can be used to record parameters, metrics and artifacts every time a model is trained. All of this information is presented in a very nice user interface.
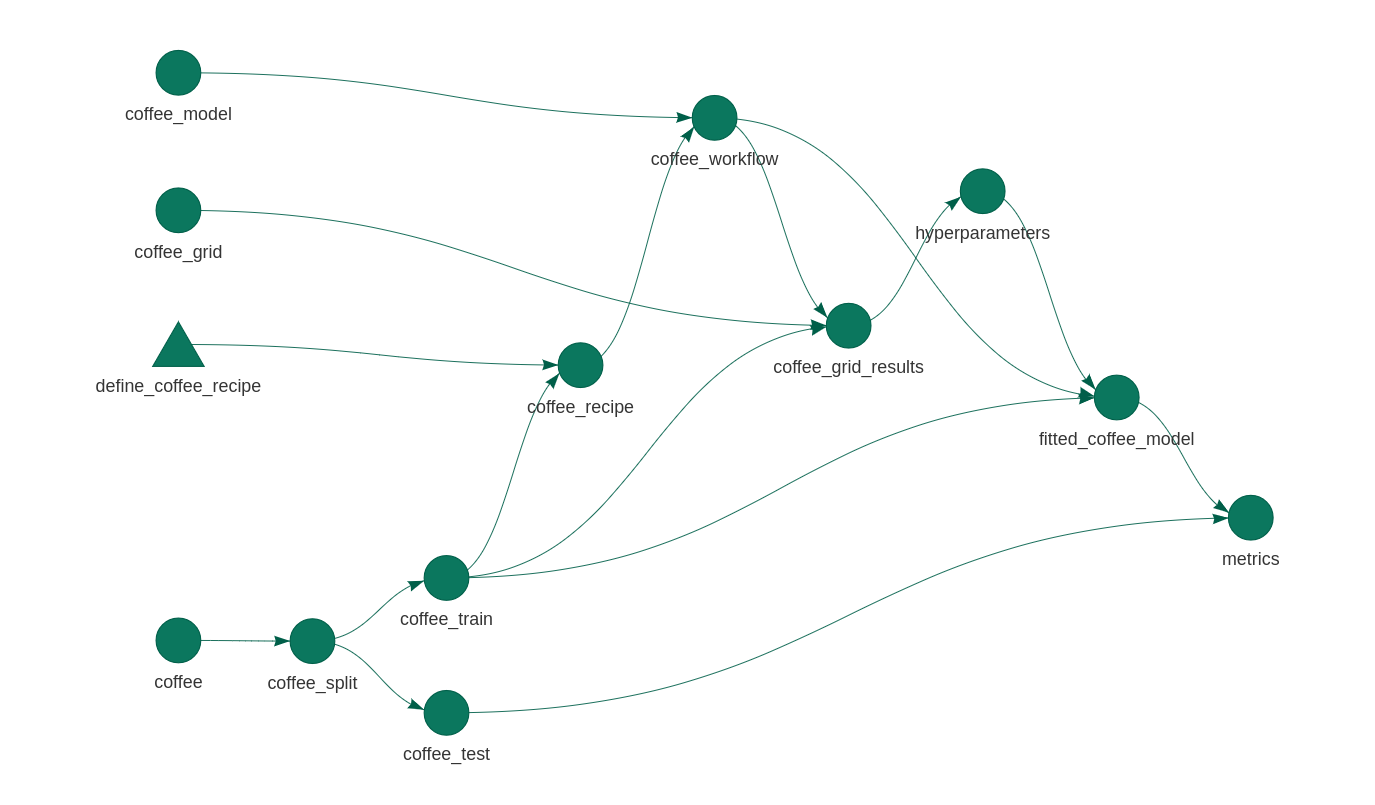
There’s always a need for more tidymodels examples on the Internet. Here’s a simple machine learning model using the recent coffee Tidy Tuesday data set. The plot above gives the approach: I’ll define some preprocessing and a model, optimise some hyperparameters, and fit and evaluate the result. And I’ll piece all of the components together using targets, an experimental alternative to the drake package that I love so much.
As usual, I don’t care too much about the model itself.
I’m obsessed with how to structure a data science project. The time I spend worrying about project structure would be better spent on actually writing code. Here’s my preferred R workflow, and a few notes on Python as well.
The R package workflow In R, the package is “the fundamental unit of shareable code”.
At rstudio::conf 2020, Hadley gave a rule of thumb for when to create a package, which I’ll paraphrase: “When you copy and paste a block of code three times, make a function.
Suppose I want a function that runs some setup code before it runs the first time. Maybe I’m using dplyr but I haven’t properly declared all of my dplyr calls in my function, so I want to run library(dplyr) before the actual function is run. Or maybe I want to install a package if it isn’t already installed, or restore a renv file, or any other setup process. I only want this special code to run the first time my function is called.
MLflow is a platform for the “machine learning cycle”. It’s a suite of tools for managing models, with tracking of hyperparameters and metrics, a registry of models, and options for serving. It’s this last bit that I’m going to focus on today.
I haven’t been able to find much discussion or documentation about MLflow’s support for R. There’s the RStudio MLflow example, but I wanted to see if I could use MLflow to serve something more complex.
As of 2023 the material in this post no longer functions due to changes in GitHub Actions.
Machine learning models get stuck at the deployment stage all the time. This stuff is hard.
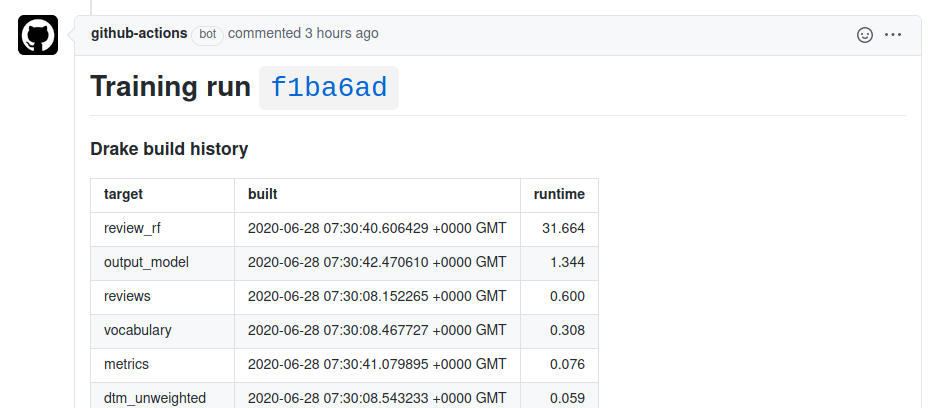
GitHub Actions is a tool for automating tasks associated with a repository. I wanted to see if I could implement some sort of end-to-end automatic training, deployment and execution of a model. And I’m going to use R because people keep telling me that this sort of stuff can’t be done with R.
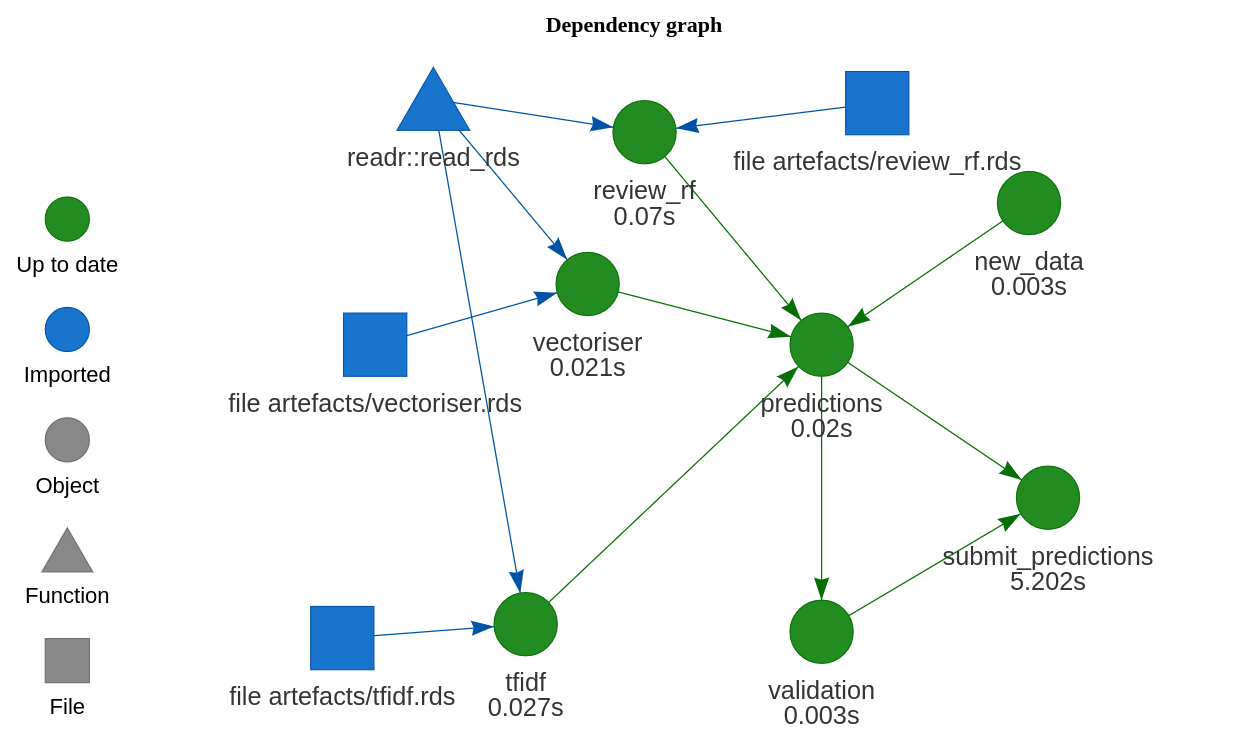
Drake is my new favourite R package.
Drake is a tool for orchestrating complicated workflows. You piece together a plan based on some high-level, abstract functions. These functions should be pure — they need to be defined by their inputs only, not relying on any predefined variables that aren’t in the function signature. Then, drake will take the steps in that plan and work out how to run it. Here’s how I’ve defined the plan above:
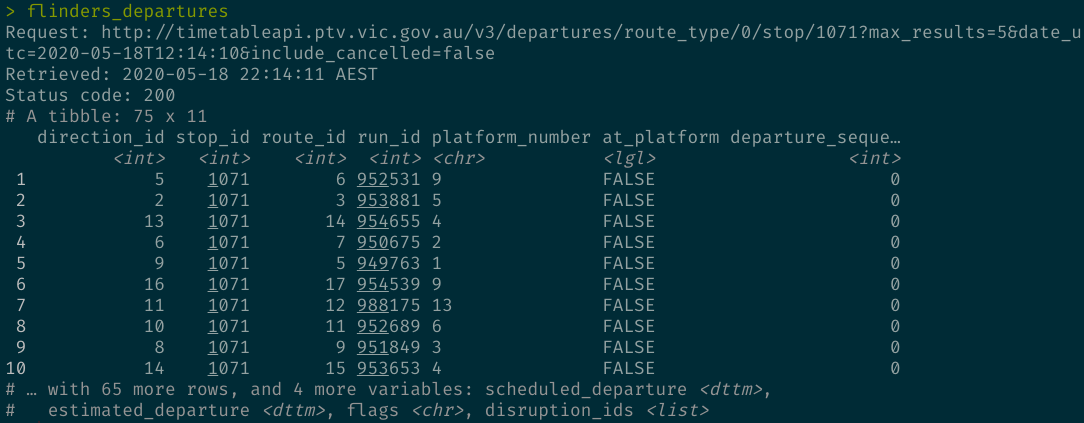
I’m creating an R API wrapper around my state’s public transport service. To make life easier for the users, the responses from the API calls are parsed and returned as tibbles/data frames. To make life easier for me, I need to keep track of the API call behind each tibble. I do this by using the tibble::new_tibble() function to attach metadata to the tibble as attributes, and creating a custom print method to make the metadata visible.